 Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam

ReAct Prompting
Theo: https://www.promptingguide.ai/techniques/react
Yao và cộng sự, 2022 đã giới thiệu một khuôn khổ có tên ReAct, trong đó các mô hình ngôn ngữ lớn - LLM (Large Language Model) được sử dụng để tạo ra cả dấu vết suy luận và các hành động cụ thể theo nhiệm vụ một cách đan xen.
Việc tạo ra dấu vết suy luận cho phép mô hình tạo ra, theo dõi và cập nhật các kế hoạch hành động, và thậm chí xử lý các trường hợp ngoại lệ. Bước hành động này cho phép giao tiếp và thu thập thông tin từ các nguồn bên ngoài như cơ sở kiến thức hoặc môi trường.
Khuôn khổ ReAct có thể cho phép các LLM tương tác với các công cụ bên ngoài để thu thập thêm thông tin, dẫn đến các phản hồi đáng tin cậy và thực tế hơn.
Kết quả cho thấy ReAct có thể vượt trội hơn một số nền tảng tiên tiến về ngôn ngữ và các nhiệm vụ ra quyết định. ReAct cũng giúp cải thiện khả năng diễn giải và độ tin cậy của LLM đối với con người. Nhìn chung, các tác giả nhận thấy rằng phương pháp tiếp cận tốt nhất là sử dụng ReAct kết hợp với chuỗi tư duy - CoT (Chain-of-thought), cho phép sử dụng cả kiến thức nội bộ và thông tin bên ngoài thu được trong quá trình suy luận.
Cách thức hoạt động?
ReAct được lấy cảm hứng từ sự đồng vận giữa "hành động" và "lý luận", cho phép con người học các nhiệm vụ mới và đưa ra quyết định hoặc lý luận.
Phương pháp lời nhắc chuỗi tư duy (CoT) đã cho thấy khả năng của LLM trong việc thực hiện các dấu vết suy luận để tạo ra câu trả lời cho các câu hỏi liên quan đến số học và suy luận thông thường, cùng với các nhiệm vụ khác (Wei và cộng sự, 2022). Tuy nhiên, việc thiếu khả năng tiếp cận thế giới bên ngoài hoặc không thể cập nhật kiến thức có thể dẫn đến các vấn đề như ảo giác sự thật và lan truyền lỗi.
ReAct là một mô hình chung kết hợp suy luận và hành động với LLM. ReAct gợi ý cho LLM tạo ra các dấu vết lý luận bằng lời nói và hành động cho một nhiệm vụ. Điều này cho phép hệ thống thực hiện việc suy luận động để tạo lập, duy trì và điều chỉnh các kế hoạch hành động, đồng thời cho phép tương tác với môi trường bên ngoài (ví dụ: Wikipedia) để kết hợp thông tin bổ sung vào suy luận. Hình dưới đây minh họa một ví dụ về ReAct và các bước khác nhau liên quan để thực hiện trả lời câu hỏi.

Image Source: Yao et al., 2022
Trong ví dụ trên, chúng ta truyền một lời nhắc như câu hỏi sau đây từ HotpotQA:
Ngoài Apple Remote, còn có thiết bị nào khác có thể kiểm soát chương trình mà Apple Remote ban đầu được thiết kế để tương tác hay không? (Aside from the Apple Remote, what other devices can control the program Apple Remote was originally designed to interact with?)
Lưu ý rằng các ví dụ trong ngữ cảnh đó cũng được thêm vào lời nhắc, nhưng chúng tôi loại trừ điều đó ở đây để đơn giản hóa. Chúng ta có thể thấy rằng mô hình tạo ra các quỹ đạo giải quyết nhiệm vụ (Suy nghĩ, Hành động). Quan sát tương ứng với quan sát từ môi trường đang được tương tác (ví dụ: Công cụ tìm kiếm). Về bản chất, ReAct có thể truy xuất thông tin để hỗ trợ suy luận, trong khi suy luận giúp xác định mục tiêu cần truy xuất tiếp theo.
Lời nhắc ReAct
Để minh họa cách thức hoạt động của lời nhắc ReAct, hãy xem xét một ví dụ từ bài báo.
Bước đầu tiên là chọn các trường hợp từ tập huấn luyện (ví dụ: HotPotQA) và tạo ra các quỹ đạo định dạng ReAct. Chúng được sử dụng như các ví dụ mẫu trong các lời nhắc. Các quỹ đạo bao gồm nhiều bước suy nghĩ-hành động-quan sát như được hiển thị trong hình trên. Các suy nghĩ dạng tự do được sử dụng để hoàn thành các nhiệm vụ khác nhau như phân tích câu hỏi, trích xuất thông tin, thực hiện suy luận thông thường/số học, hướng dẫn việc tìm kiếm và tổng hợp câu trả lời cuối cùng.
Sau đây là một ví dụ về hình thức của lời nhắc ReAct (lấy từ bài báo và rút gọn thành một ví dụ để đơn giản hơn):
Câu hỏi Phạm vi độ cao của khu vực mà phần phía đông của tạo núi Colorado kéo dài đến là bao nhiêu?
Suy nghĩ 1 Tôi cần tìm kiếm tạo núi Colorado, tìm khu vực mà phần phía đông của tạo núi Colorado kéo dài đến, sau đó tìm phạm vi độ cao của khu vực đó.
Hành động 1 Tìm kiếm [tạo núi Colorado]
Quan sát 1 Tạo núi Colorado là một giai đoạn kiến tạo núi (tạo núi) ở Colorado và các khu vực xung quanh.
Suy nghĩ 2 Nó không đề cập đến phần phía đông. Vì vậy, tôi cần tra cứu phần phía đông.
Hành động 2 Tra cứu [phần phía đông]
Quan sát 2 (Kết quả 1 / 1) Phần phía đông kéo dài đến Cao nguyên và được gọi là tạo núi Đồng bằng Trung tâm.
Suy nghĩ 3 Phần phía đông của tạo núi Colorado kéo dài đến Cao nguyên. Vì vậy, tôi cần tìm kiếm Cao nguyên và tìm phạm vi độ cao của nó.
Hành động 3 Tìm kiếm [Vùng Cao]
Quan sát 3 Vùng Cao đề cập đến một trong hai vùng đất riêng biệt
Suy nghĩ 4 Thay vào đó, tôi cần tìm kiếm Vùng Cao (Hoa Kỳ).
Hành động 4 Tìm kiếm [Vùng Cao (Hoa Kỳ)]
Quan sát 4 Vùng Cao là một tiểu vùng của Đại Bình nguyên. Từ đông sang tây, vùng Cao cao tăng dần độ cao từ khoảng 1.800 đến 7.000 ft (550 đến 2.130 m).[3]
Suy nghĩ 5 Vùng Cao tăng dần độ cao từ khoảng 1.800 đến 7.000 ft, vì vậy đáp án là 1.800 đến 7.000 ft.
...
Lưu ý rằng các thiết lập lời nhắc khác nhau được sử dụng cho các loại nhiệm vụ khác nhau. Đối với các nhiệm vụ mà suy luận là yếu tố quan trọng hàng đầu (ví dụ: HotpotQA), nhiều bước suy nghĩ-hành động-quan sát được sử dụng cho lộ trình giải quyết nhiệm vụ. Đối với các nhiệm vụ ra quyết định bao gồm nhiều bước hành động, suy nghĩ được sử dụng ít hơn.

Video: Building a ReAct AI Agent (Tutorial)
Kết quả các nhiệm vụ chuyên sâu về kiến thức
Bài báo đầu tiên đánh giá ReAct trong các nhiệm vụ suy luận chuyên sâu về kiến thức như trả lời câu hỏi (HotPotQA) và xác minh sự thật (Fever). PaLM-540B được sử dụng làm mô hình cơ sở cho việc nhắc.
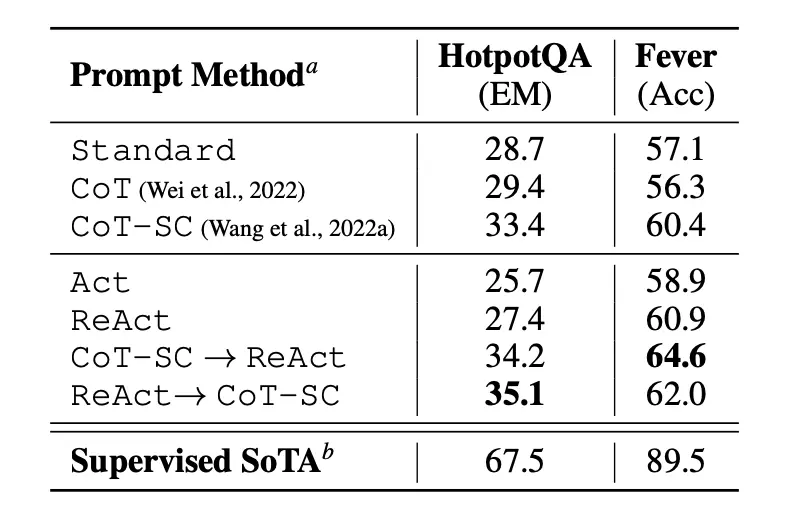
Image Source: Yao et al., 2022
Kết quả của lời nhắc trong HotPotQA và Fever khi sử dụng các phương pháp nhắc khác nhau cho thấy ReAct nhìn chung hoạt động tốt hơn Act (chỉ bao gồm hành động) ở cả hai nhiệm vụ.
Chúng ta cũng có thể thấy ReAct hoạt động tốt hơn CoT trên Fever và chậm hơn CoT trên HotpotQA. Bài báo đã cung cấp một phân tích lỗi chi tiết. Tóm lại:
CoT bị ảo giác thực tế
Ràng buộc về cấu trúc của ReAct làm giảm tính linh hoạt trong việc xây dựng các bước suy luận
ReAct phụ thuộc rất nhiều vào thông tin mà nó đang thu thập; kết quả tìm kiếm không cung cấp thông tin sẽ làm chệch hướng suy luận của mô hình và dẫn đến khó khăn trong việc khôi phục và định hình lại các ý tưởng.
Các phương pháp lời nhắc kết hợp và hỗ trợ chuyển đổi giữa ReAct và CoT + Tự nhất quán thường hoạt động tốt hơn tất cả các phương pháp lời nhắc khác.
Kết quả trong các Nhiệm vụ Ra quyết định
Bài báo cũng báo cáo các kết quả chứng minh hiệu suất của ReAct trong các nhiệm vụ ra quyết định. ReAct được đánh giá dựa trên hai tiêu chuẩn là ALFWorld (trò chơi dựa trên văn bản) và WebShop (môi trường trang web mua sắm trực tuyến). Cả hai đều liên quan đến các môi trường phức tạp đòi hỏi khả năng suy luận để hành động và khám phá hiệu quả.
Lưu ý rằng các lời nhắc ReAct được thiết kế khác nhau cho các nhiệm vụ này nhưng vẫn giữ nguyên ý tưởng cốt lõi là kết hợp suy luận và hành động. Dưới đây là một ví dụ về bài toán ALFWorld liên quan đến lời nhắc ReAct.
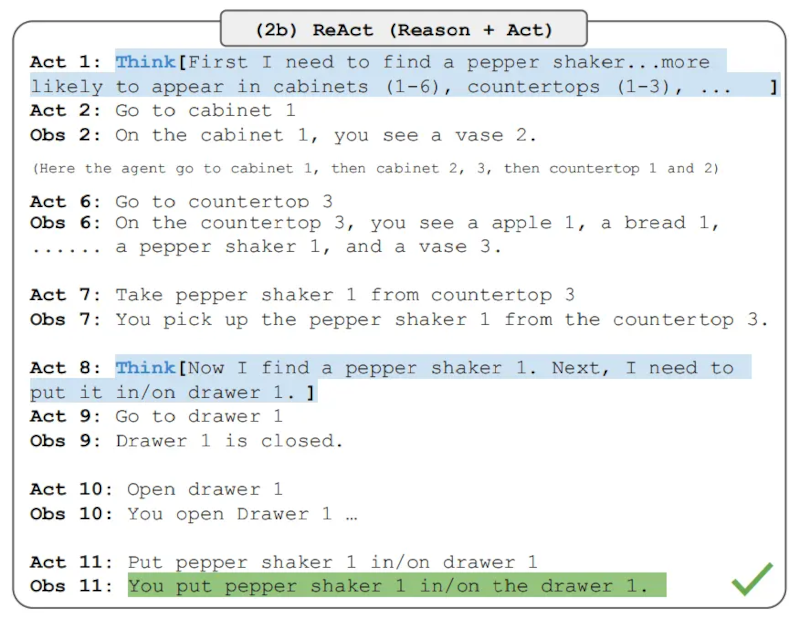
Image Source: Yao et al., 2022
ReAct vượt trội hơn Act trên cả ALFWorld và Webshop. Hành động, nếu không có tư duy, sẽ không thể phân tích chính xác các mục tiêu thành các mục tiêu con. Suy luận dường như có lợi thế trong ReAct cho các loại nhiệm vụ này, nhưng các phương pháp dựa trên lời nhắc hiện tại vẫn còn kém xa hiệu suất của con người chuyên nghiệp trong các nhiệm vụ này.
Xem bài báo để biết kết quả chi tiết hơn.
Sử dụng LangChain ReAct
Dưới đây là một ví dụ cụ thể về cách thức hoạt động của phương pháp gợi ý ReAct trong thực tế. Chúng tôi sẽ sử dụng OpenAI cho LLM và LangChain vì nó đã có sẵn chức năng tích hợp tận dụng khung ReAct để xây dựng các tác nhân thực hiện nhiệm vụ bằng cách kết hợp sức mạnh của LLM và các công cụ khác nhau.
Trước tiên, hãy cài đặt và nhập các thư viện cần thiết:
%%capture
# cập nhật hoặc cài đặt các thư viện cần thiết
!pip install --upgrade openai
!pip install --upgrade langchain
!pip install --upgrade python-dotenv
!pip install google-search-results
# Nhập khẩu các thư viện
import openai
import os
from langchain.llms import OpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv()
# tải lên các khóa API; bạn sẽ cần lấy những khóa này nếu chưa có
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
Bây giờ chúng ta có thể cấu hình LLM, các công cụ chúng ta sẽ sử dụng và tác nhân cho phép chúng ta tận dụng khung ReAct cùng với LLM và các công cụ. Lưu ý rằng chúng ta đang sử dụng API tìm kiếm để tìm kiếm thông tin bên ngoài và LLM như một công cụ toán học.
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)
tools = load_tools(["google-serper", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
Sau khi cấu hình xong, chúng ta có thể chạy tác nhân với truy vấn/lời nhắc mong muốn. Lưu ý rằng ở đây chúng ta không cần cung cấp các ví dụ ít ỏi như đã giải thích trong bài báo.
agent.run("Bạn trai của Olivia Wilde là ai? Tuổi hiện tại của anh ấy là bao nhiêu lũy thừa 0,23?")
Chuỗi thực hiện trông như sau:
> Nhập vào chuỗi AgentExecutor mới...
Tôi cần tìm ra bạn trai của Olivia Wilde là ai và sau đó tính tuổi của anh ấy lũy thừa 0,23.
Hành động: Tìm kiếm
Đầu vào hành động: “bạn trai của Olivia Wilde"
Quan sát thấy: Olivia Wilde bắt đầu hẹn hò với Harry Styles sau khi chấm dứt mối quan hệ kéo dài nhiều năm với Jason Sudeikis — xem dòng thời gian mối quan hệ của họ.
Suy luận: Tôi cần tìm ra tuổi của Harry Styles
Hành động: Tìm kiếm
Đầu vào hành động: “Tuổi của Harry Styles”
Quan sát thấy: 29 tuổi
Suy luận: Tôi cần tính 29 lũy thừa 0,23
Hành động: Tính toán
Đầu vào hành động:29^0.23
Quan sát thấy: Đáp án: 2.169459462491557
Suy luận: Giờ tôi đã biết đáp án cuối cùng.
Câu trả lời cuối cùng: Harry Styles, bạn trai của Olivia Wilde, 29 tuổi và tuổi của anh ấy lũy thừa 0,23 là 2,169459462491557.
> Chuỗi đã hoàn thành.
Kết quả đầu ra chúng ta nhận được như sau:
"Harry Styles, bạn trai của Olivia Wilde, 29 tuổi và tuổi của anh ấy lũy thừa 0,23 là 2,169459462491557."
Chúng tôi đã điều chỉnh ví dụ từ tài liệu LangChain, vì vậy công lao thuộc về họ. Chúng tôi khuyến khích người học khám phá các cách kết hợp công cụ và nhiệm vụ khác nhau.
Bạn có thể tìm thấy sổ ghi chép cho mã này tại đây: https://github.com/dair-ai/Prompt-Engineering-Guide/blob/main/notebooks/react.ipynb
Về ‘Kỹ thuật viết lời nhắc’ ………. Phần trước ………. Phần tiếp theo
Yao et al., 2022 introduced a framework named ReAct where LLMs are used to generate both reasoning traces and task-specific actions in an interleaved manner.
Generating reasoning traces allow the model to induce, track, and update action plans, and even handle exceptions. The action step allows to interface with and gather information from external sources such as knowledge bases or environments.
The ReAct framework can allow LLMs to interact with external tools to retrieve additional information that leads to more reliable and factual responses.
Results show that ReAct can outperform several state-of-the-art baselines on language and decision-making tasks. ReAct also leads to improved human interpretability and trustworthiness of LLMs. Overall, the authors found that best approach uses ReAct combined with chain-of-thought (CoT) that allows use of both internal knowledge and external information obtained during reasoning.
ReAct is inspired by the synergies between "acting" and "reasoning" which allow humans to learn new tasks and make decisions or reasoning.
Chain-of-thought (CoT) prompting has shown the capabilities of LLMs to carry out reasoning traces to generate answers to questions involving arithmetic and commonsense reasoning, among other tasks (Wei et al., 2022). But its lack of access to the external world or inability to update its knowledge can lead to issues like fact hallucination and error propagation.
ReAct is a general paradigm that combines reasoning and acting with LLMs. ReAct prompts LLMs to generate verbal reasoning traces and actions for a task. This allows the system to perform dynamic reasoning to create, maintain, and adjust plans for acting while also enabling interaction to external environments (e.g., Wikipedia) to incorporate additional information into the reasoning. The figure below shows an example of ReAct and the different steps involved to perform question answering.
In the example above, we pass a prompt like the following question from HotpotQA:
Aside from the Apple Remote, what other devices can control the program Apple Remote was originally designed to interact with?
Note that in-context examples are also added to the prompt but we exclude that here for simplicity. We can see that the model generates task solving trajectories (Thought, Act). Obs corresponds to observation from the environment that's being interacted with (e.g., Search engine). In essence, ReAct can retrieve information to support reasoning, while reasoning helps to target what to retrieve next.
To demonstrate how ReAct prompting works, let's follow an example from the paper.
The first step is to select cases from a training set (e.g., HotPotQA) and compose ReAct-format trajectories. These are used as few-shot exemplars in the prompts. The trajectories consist of multiple thought-action-observation steps as shown in the figure above. The free-form thoughts are used to achieve different tasks such as decomposing questions, extracting information, performing commonsense/arithmetic reasoning, guide search formulation, and synthesizing final answer.
Here is an example of what the ReAct prompt exemplars look like (obtained from the paper and shortened to one example for simplicity):
Question What is the elevation range for the area that the eastern sector of theColorado orogeny extends into?Thought 1 I need to search Colorado orogeny, find the area that the eastern sectorof the Colorado orogeny extends into, then find the elevation range of thearea.Action 1 Search[Colorado orogeny]Observation 1 The Colorado orogeny was an episode of mountain building (an orogeny) inColorado and surrounding areas.Thought 2 It does not mention the eastern sector. So I need to look up easternsector.Action 2 Lookup[eastern sector]Observation 2 (Result 1 / 1) The eastern sector extends into the High Plains and is calledthe Central Plains orogeny.Thought 3 The eastern sector of Colorado orogeny extends into the High Plains. So Ineed to search High Plains and find its elevation range.Action 3 Search[High Plains]Observation 3 High Plains refers to one of two distinct land regionsThought 4 I need to instead search High Plains (United States).Action 4 Search[High Plains (United States)]Observation 4 The High Plains are a subregion of the Great Plains. From east to west, theHigh Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130m).[3]Thought 5 High Plains rise in elevation from around 1,800 to 7,000 ft, so the answeris 1,800 to 7,000 ft.Action 5 Finish[1,800 to 7,000 ft]...
Note that different prompts setups are used for different types of tasks. For tasks where reasoning is of primary importance (e.g., HotpotQA), multiple thought-action-observation steps are used for the task-solving trajectory. For decision making tasks involving lots of action steps, thoughts are used sparsely.
Results on Knowledge-Intensive Tasks
The paper first evaluates ReAct on knowledge-intensive reasoning tasks such as question answering (HotPotQA) and fact verification (Fever). PaLM-540B is used as the base model for prompting
The prompting results on HotPotQA and Fever using different prompting methods show that ReAct generally performs better than Act (involves acting only) on both tasks.
We can also observe that ReAct outperforms CoT on Fever and lags behind CoT on HotpotQA. A detailed error analysis is provided in the paper. In summary:
CoT suffers from fact hallucination
ReAct's structural constraint reduces its flexibility in formulating reasoning steps
ReAct depends a lot on the information it's retrieving; non-informative search results derails the model reasoning and leads to difficulty in recovering and reformulating thoughts
Prompting methods that combine and support switching between ReAct and CoT+Self-Consistency generally outperform all the other prompting methods.
Results on Decision Making Tasks
The paper also reports results demonstrating ReAct's performance on decision making tasks. ReAct is evaluated on two benchmarks called ALFWorld (text-based game) and WebShop (online shopping website environment). Both involve complex environments that require reasoning to act and explore effectively.
Note that the ReAct prompts are designed differently for these tasks while still keeping the same core idea of combining reasoning and acting. Below is an example for an ALFWorld problem involving ReAct prompting.
ReAct outperforms Act on both ALFWorld and Webshop. Act, without any thoughts, fails to correctly decompose goals into subgoals. Reasoning seems to be advantageous in ReAct for these types of tasks but current prompting-based methods are still far from the performance of expert humans on these tasks.
Check out the paper for more detailed results.
Below is a high-level example of how the ReAct prompting approach works in practice. We will be using OpenAI for the LLM and LangChain as it already has built-in functionality that leverages the ReAct framework to build agents that perform tasks by combining the power of LLMs and different tools.
First, let's install and import the necessary libraries:
%%capture# update or install the necessary libraries!pip install --upgrade openai!pip install --upgrade langchain!pip install --upgrade python-dotenv!pip install google-search-results# import librariesimport openaiimport osfrom langchain.llms import OpenAIfrom langchain.agents import load_toolsfrom langchain.agents import initialize_agentfrom dotenv import load_dotenvload_dotenv()# load API keys; you will need to obtain these if you haven't yetos.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
Now we can configure the LLM, the tools we will use, and the agent that allows us to leverage the ReAct framework together with the LLM and tools. Note that we are using a search API for searching external information and LLM as a math tool.
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)tools = load_tools(["google-serper", "llm-math"], llm=llm)agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
Once that's configured, we can now run the agent with the desired query/prompt. Notice that here we are not expected to provide few-shot exemplars as explained in the paper.
agent.run("Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?")
The chain execution looks as follows:
> Entering new AgentExecutor chain...I need to find out who Olivia Wilde's boyfriend is and then calculate his age raised to the 0.23 power.Action: SearchAction Input: "Olivia Wilde boyfriend"Observation: Olivia Wilde started dating Harry Styles after ending her years-long engagement to Jason Sudeikis — see their relationship timeline.Thought: I need to find out Harry Styles' age.Action: SearchAction Input: "Harry Styles age"Observation: 29 yearsThought: I need to calculate 29 raised to the 0.23 power.Action: CalculatorAction Input: 29^0.23Observation: Answer: 2.169459462491557Thought: I now know the final answer.Final Answer: Harry Styles, Olivia Wilde's boyfriend, is 29 years old and his age raised to the 0.23 power is 2.169459462491557.> Finished chain.
The output we get is as follows:
"Harry Styles, Olivia Wilde's boyfriend, is 29 years old and his age raised to the 0.23 power is 2.169459462491557."
We adapted the example from the LangChain documentation, so credit goes to them. We encourage the learner to explore different combination of tools and tasks.
You can find the notebook for this code here: https://github.com/dair-ai/Prompt-Engineering-Guide/blob/main/notebooks/react.ipynb
Dịch: Lê Trung Nghĩa
letrungnghia.foss@gmail.com
Tác giả: Nghĩa Lê Trung
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Blog này được chuyển đổi từ http://blog.yahoo.com/letrungnghia trên Yahoo Blog sang sử dụng NukeViet sau khi Yahoo Blog đóng cửa tại Việt Nam ngày 17/01/2013.Kể từ ngày 07/02/2013, thông tin trên Blog được cập nhật tiếp tục trở lại với sự hỗ trợ kỹ thuật và đặt chỗ hosting của nhóm phát triển...
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
 ‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
 Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
 12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
 Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
 Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 ‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
 ‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
 Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Tài nguyên Giáo dục Mở trong kỷ nguyên AI
 cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
 Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
 Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025
Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025

