 Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
If DeepSeek wants to be a real disruptor, it should go much further on data transparency
Thu Jan 30, 2025
Bài được đưa lên Internet ngày: 30/01/2025
Chúng ta cần tính minh bạch nhiều hơn từ tất cả các nhà cung cấp mô hình.
Vào ngày 20/01/2025, công ty AI Trung Quốc DeepSeek đã phát hành một mô hình ngôn ngữ gọi là R1 đã gửi đi làn sóng gây sốc khắp thế giới AI trên toàn cầu. Cùng với việc phát hành là những tuyên bố ấn tượng về sự phát triển và khả năng của mô hình đó, với sự phát triển mô hình chỉ bằng 10% của chi phí được cho là của o1 của OpenAI và nhanh gần gấp đôi so với chuẩn mực. Điều đó là vì, theo báo cáo kỹ thuật, R1 ít dựa hơn vào việc gắn nhãn của con người và thay vào đó có khả năng sử dụng một dạng đào tạo được tự động hóa. Thế còn về dữ liệu thì sao? Nó tới từ đâu và nó được sử dụng như thế nào?
Chỉ số Minh bạch Dữ liệu AI
Tháng trước, Viện Dữ liệu Mở - ODI (Open Data Institute) đã phát hành Chỉ số Minh bạch Dữ liệu AI - AIDTI (AI Data Transparency Index), một khung mới để phân tích liệu các nhà cung cấp mô hình có chia sẻ thông tin cần thiết về tính minh bạch dữ liệu có ý nghĩa hay không. Với AIDTI, các nhà cung cấp mô hình được đánh giá theo 7 chiều, tìm kiếm sự minh bạch về những điều chẳng hạn như các nguồn của tập dữ liệu và các phương pháp thu thập, các hoạt động xử lý được triển khai, và liệu các tập dữ liệu đã được kiểm tra về dữ liệu có bản quyền hay dữ liệu cá nhân hay chưa.
Thông qua quá trình này, chúng tôi đã phân tích 22 mô hình từ khắp trên thế giới, bao gồm các mô hình mà cũng giống như DeepSeek đã tuyên bố là ‘nguồn mở’. Phân tích của chúng tôi đã xác định rằng:
Mức độ trưởng thành cao đã được 5 nhà cung cấp mô hình thể hiện, được đặc trưng bằng việc ghi thành tài liệu chi tiết, truy cập được, sử dụng nhất quán các công cụ minh bạch, và một cách tiếp cận chủ động tích cực cho các quyết định giải thích được tiến hành trong quá trình phát triển đó.
6 nhà cung cấp mô hình đã đáp ứng một số tiêu chí minh bạch nhưng thiếu sự nhất quán đối với tất cả các chiều và vì thế đã được coi là có mức độ trưởng thành trung bình.
11 nhà cung cấp mô hình đã thể hiện mức độ trưởng thành thấp với thông tin hạn chế hoặc chất lượng kém, gợi ý sự miễn cưỡng chung để trở thành mở.
Chúng tôi nghĩ có thể là cơ hội tốt để xem DeepSeek được so sánh như thế nào với các đối thủ cạnh tranh đã thanh danh của nó.
Hai nhà nghiên cứu của ODI đã độc lập lặp lại phương pháp Chỉ số Minh bạch Dữ liệu AI cho DeepSeek R1 và bạn có thể thấy kết quả đối sánh bên dưới.
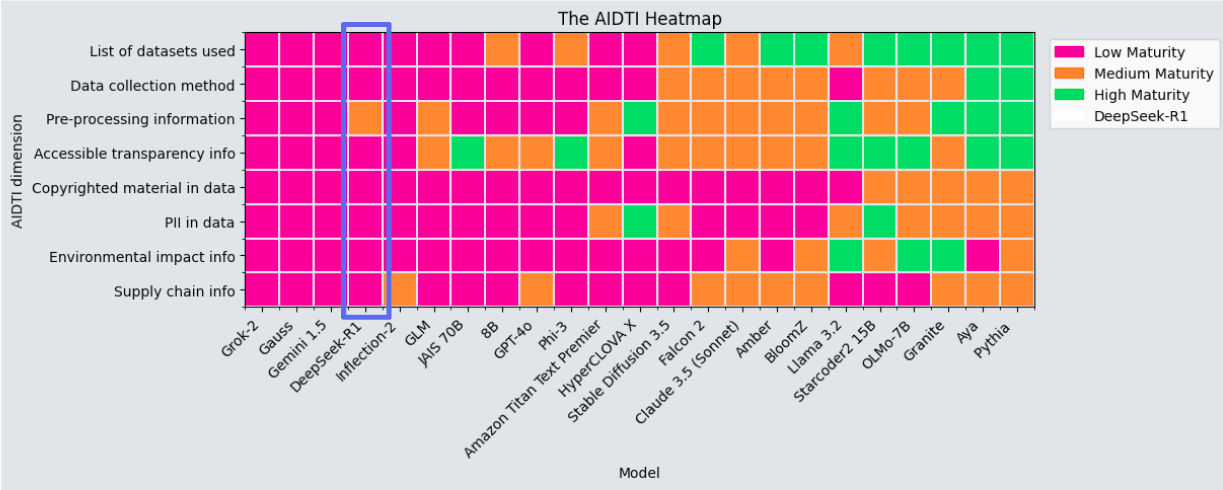
DeepSeek và minh bạch dữ liệu
DeepSeek không may đã được xếp hạng ở mức trưởng thành thấp đối với tất cả ngoại trừ 1 trong số 7 chiều minh bạch của chúng tôi. Nhờ có tóm tắt khá chi tiết các hoạt động tiền xử lý và hậu đào tạo đã diễn ra trong quá trình phát triển DeepSeek R1, DeepSeekđã có điểm trung bình về mức độ trưởng thành đối với chiều này. Đối với các chiều còn lại, DeepSeek có điểm kém. Đã có danh sách không rõ ràng về các tập dữ liệu được sử dụng trong mô hình và cơ chế không minh bạch được sử dụng (chẳng hạn như các thẻ mô hình hay dữ liệu) để giúp làm cho các mô hình AI minh bạch hơn và truy cập được nhiều hơn. Đã không có các chi tiết được chia sẻ xem dữ liệu này có bao gồm các dữ liệu có bản quyền hay thông tin cá nhân hay không, cũng không có bất kỳ sự bảo vệ nào cho điều này. Cũng như thông tin chi tiết hơn về toàn bộ chuỗi cung ứng dữ liệu. Bất chấp một số tuyên bố ấn tượng về hiệu quả tính toán của các mô hình, toàn bộ chi phí môi trường của quá trình phát triển vẫn chưa được chia sẻ.
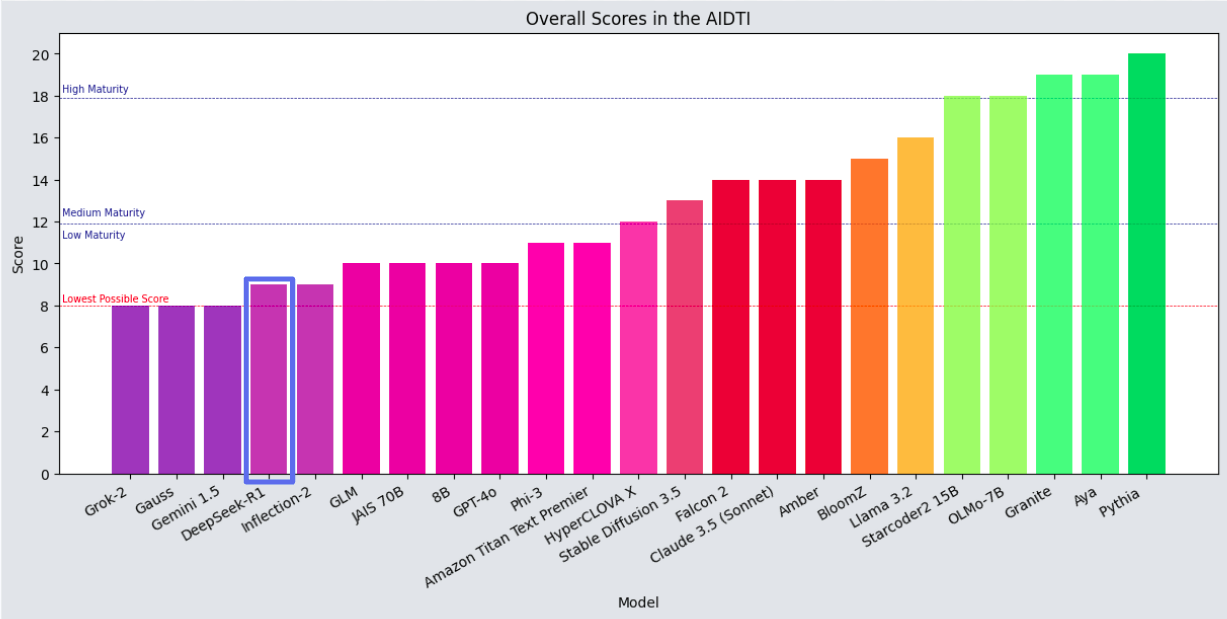
Tổng thể, mức độ trưởng thành minh bạch dữ liệu thấp của DeepSeek đặt nó ngang hàng với Inflection-2, tốt hơn một chút so với Grok 2 của X và Gemini 1.5 của Google, và khá tệ hơn so với GPT-4o của OpenAI. Tất cả các mô hình đó vẫn còn được coi là có mức độ trưởng thành thấp về minh bạch dữ liệu, và đứng xa phía sau so với Aya của Cohere và Pythia của EleutherAI. DeepSeek R1 không phải là mô hình nguồn mở, cũng không là một tiêu chuẩn mới về minh bạch dữ liệu.
Việc có mức độ trưởng thành thấp về minh bạch dữ liệu có nghĩa đối với những người dùng khác nhau rằng:
Chúng tôi không thể xác định liệu dữ liệu có được sử dụng từ đối thủ cạnh tranh của họ hay không vì OpenAI và Microsoft được cho là đang điều tra
Tính xác thực của các tuyên bố về chi phí của DeepSeek, vì nó phần lớn được khởi tạo từ một mô hình trước đó mà họ chưa công bố chi phí đào tạo
Tính xác thực của các tuyên bố về hiệu quả đào tạo của DeepSeek, mặc dù một số tính toán cho thấy chúng là sự thật
Kết luận
Mặc dù có nhiều tuyên bố về mô hình AI 'nguồn mở' của DeepSeek, nhưng thực tế thì nó không phải là nguồn mở. Mặc dù cả trọng số mô hình và kiến trúc mô hình đều được chia sẻ trong một bài báo kỹ thuật, nhưng cả mã lẫn dữ liệu đào tạo hoặc đánh giá đều không được chia sẻ công khai. Một nhà phân tích của Sáng kiến Nguồn Mở cũng xác nhận rằng Deepseek không phải là AI Nguồn Mở và không đáp ứng các yêu cầu của định nghĩa AI Nguồn Mở (bản dịch sang tiếng Việt). Nó tham gia cùng các mô hình khác tuyên bố là nguồn mở, nhưng lại có điểm kém về tính minh bạch dữ liệu.
Cuối cùng, điều này có nghĩa là nhiều tuyên bố ấn tượng của DeepSeek về phát triển mô hình hiệu quả cao không thể được xác thực. Để điều này thực sự là một sự kiện mang tính đột phá, DeepSeek sẽ phải trở nên trưởng thành hơn nhiều với thông tin về tính minh bạch dữ liệu mà họ chia sẻ.
Nhìn chung, tính minh bạch dữ liệu vẫn tiếp tục là một cơ chế có liên quan để đánh giá các mô hình và nhà cung cấp mới. Chúng ta cần nhiều tính minh bạch hơn, không chỉ từ DeepSeek vì một số người lo sợ về nguồn dữ liệu và rủi ro về quyền riêng tư đối với người dùng, mà còn từ tất cả các nhà cung cấp mô hình dù là người Mỹ hay người Trung Quốc, mở hay đóng, lớn hay nhỏ.
Xem thêm:
We need more transparency, from all model providers.
On January 20th, the Chinese AI company DeepSeek released a language model called R1 which sent shockwaves across the global AI world. Accompanying the release were impressive claims regarding the model's development and capability, with the development of a model that is 10% of the supposed cost of OpenAI’s o1 and nearly twice as fast on benchmarks. That’s because, according to the technical report, R1 was less reliant on human labelling and instead was able to use an automated form of training. But what about the data? Where did it come from and how is it used?
The AI Data Transparency Index
Last month, the ODI launched the AI Data Transparency Index, a new framework to analyse whether model providers were sharing the information needed for meaningful data transparency. With the AIDTI model providers are assessed across seven dimensions, looking for transparency on things such as dataset sources and collection methods, processing activities carried out, and whether the datasets have been checked for copyrighted or personal data.
Through this process, we analysed 22 models from around the world, including models that also, like DeepSeek claimed to be ‘open source’. Our analysis identified that:
High maturity was demonstrated by five model providers, characterised by detailed, accessible documentation, consistent use of transparency tools, and a proactive approach to explaining decisions made in the development process.
Six model providers met some transparency criteria but lacked consistency for all dimensions and were therefore considered medium maturity.
Eleven model providers demonstrated low maturity with limited or poor-quality information, suggesting a general reluctance to be open.
We thought it would be a good opportunity to see how DeepSeek compared to its established competitors.
Two ODI researchers independently repeated our AI Data Transparency Index methodology for DeepSeek R1 and you can see the comparative results below.
Deepseek and data transparency
DeepSeek was unfortunately ranked at low maturity for all but one of our seven transparency dimensions. Due to relatively detailed summaries of the pre-processing and post-training activities that took place in developing DeepSeek R1, DeepSeek was scored at medium maturity for this. For the rest of them, DeepSeek scored poorly. There was no clear list of datasets used in the model and no transparent mechanism used (such as model or data cards) which help to make AI models more transparent and accessible. There were no details shared on whether this data included copyrighted data or personal information, nor any protections for this in place. As was further information on the full data supply chain. Despite some impressive claims as to the models compute efficiency, full environmental costs of the development were not shared.
Overall, DeepSeek’s low data transparency maturity puts it on a par with Inflection-2, moderately better than X’s Grok 2 and Google’s Gemini 1.5, and marginally worse than OpenAI’s GPT-4o. All of these models are still considered low maturity in data transparency, and languish far behind the likes of Cohere’s Aya and EleutherAI’s Pythia. DeepSeek R1 is not an open source model, nor is it a new standard for data transparency.
Being low maturity for data transparency means for different users that:
We can’t identify whether data was used from their competitors as OpenAI and Microsoft are reportedly probing
The veracity of DeepSeek’s cost claims, as it was largely bootstrapped from a previous model that they haven’t released the training costs for
The veracity of DeepSeek’s training efficiency claims, although some calculations suggest there is truth to them
Conclusion
While there are multiple claims to DeepSeek’s ‘open source’ AI model, in reality it is not open source. While both the model weights and the model architecture were shared in a technical paper, neither the code nor the training or evaluation data were shared openly. An analyst for the Open Source Initiative also confirmed that Deepseek is not Open Source AI and doesn’t meet the requirements of the Open Source AI definition. It joins other models which claim to be open source, but score poorly on data transparency.
Ultimately, this means that many of DeepSeek’s impressive claims to highly-efficient model development cannot be validated. For this truly to be a disruptive event, DeepSeek will be required to become much more mature with the data transparency information they share.
Overall, data transparency continues to be a relevant mechanism for judging new models and providers.We need more transparency, not just from DeepSeek because some people are fearful over the sources of the data and privacy risks for users, but from all model providers whether American or Chinese, open or closed, massive or tiny.
Dịch: Lê Trung Nghĩa
letrungnghia.foss@gmail.com
Tác giả: Nghĩa Lê Trung
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Blog này được chuyển đổi từ http://blog.yahoo.com/letrungnghia trên Yahoo Blog sang sử dụng NukeViet sau khi Yahoo Blog đóng cửa tại Việt Nam ngày 17/01/2013.Kể từ ngày 07/02/2013, thông tin trên Blog được cập nhật tiếp tục trở lại với sự hỗ trợ kỹ thuật và đặt chỗ hosting của nhóm phát triển...
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
 ‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
 Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
 12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
 Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
 Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 ‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
 ‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
 Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Tài nguyên Giáo dục Mở trong kỷ nguyên AI
 cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
 Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
 Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025
Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025

