 Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam

Reflexion
Theo: https://www.promptingguide.ai/techniques/reflexion
Phản xạ là một khuôn khổ để củng cố các tác nhân dựa trên ngôn ngữ thông qua phản hồi ngôn ngữ. Theo Shinn và cộng sự (2023), "Phản xạ là một mô hình mới cho việc củng cố 'bằng lời nói', tham số hóa chính sách thành mã hóa bộ nhớ của tác nhân kết hợp với các tham số LLM được lựa chọn."
Ở cấp độ cao, Phản xạ chuyển đổi phản hồi (dạng ngôn ngữ tự do hoặc dạng vô hướng) từ môi trường thành phản hồi ngôn ngữ, còn được gọi là tự phản xạ (self-reflection), được cung cấp làm bối cảnh cho tác nhân LLM trong hành động tiếp theo. Điều này giúp tác nhân học hỏi nhanh chóng và hiệu quả từ những sai lầm trước đó, dẫn đến cải thiện hiệu suất trong nhiều tác vụ nâng cao.
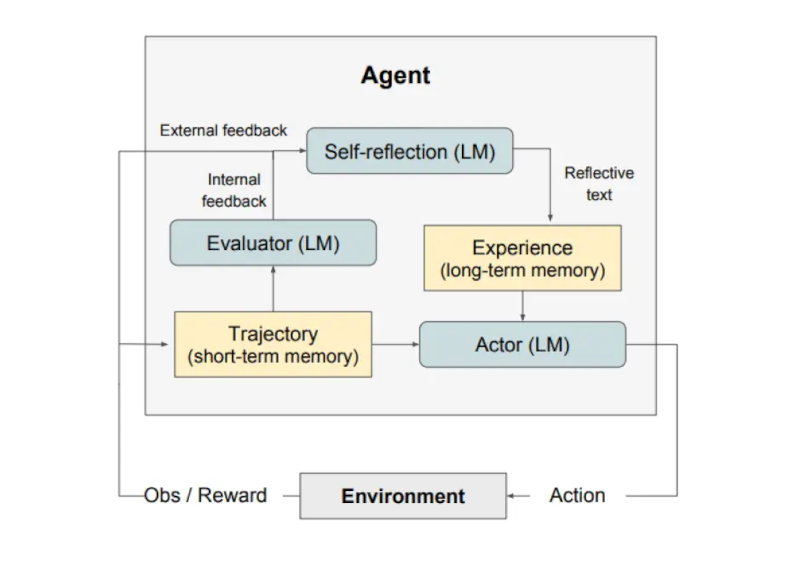
Như được minh họa trong hình ở trên, Reflexion gồm 3 mô hình riêng biệt:
Một Actor (Người hành động): Tạo văn bản và hành động dựa trên các quan sát trạng thái. Actor thực hiện một hành động trong môi trường và nhận được một quan sát, từ đó tạo ra một quỹ đạo. Chuỗi Tư duy - CoT (Chain-of-Thought) và ReAct được sử dụng làm mô hình Actor. Một thành phần bộ nhớ cũng được thêm vào để cung cấp thêm ngữ cảnh cho tác nhân.
Một Evaluator (Người đánh giá): Chấm điểm các kết quả đầu ra do Actor tạo ra. Cụ thể, nó lấy đầu vào là một quỹ đạo đã được tạo ra (còn được gọi là bộ nhớ ngắn hạn) và đưa ra điểm thưởng. Các hàm thưởng khác nhau được sử dụng tùy thuộc vào nhiệm vụ (LLM và phương pháp tìm kiếm dựa trên quy tắc được sử dụng cho các nhiệm vụ ra quyết định).
Tự phản ánh (Self-Reflection): Tạo ra các tín hiệu củng cố bằng lời nói để hỗ trợ Actor trong việc tự cải thiện. Vai trò này được thực hiện bởi một LLM và cung cấp phản hồi có giá trị cho các thử nghiệm trong tương lai. Để tạo ra phản hồi cụ thể và có liên quan, điều cũng được lưu trữ trong bộ nhớ, mô hình tự phản ánh sử dụng tín hiệu thưởng, quỹ đạo hiện tại và bộ nhớ liên tục của nó. Những kinh nghiệm này (được lưu trữ trong bộ nhớ dài hạn) được tác nhân tận dụng để cải thiện nhanh chóng quá trình ra quyết định.
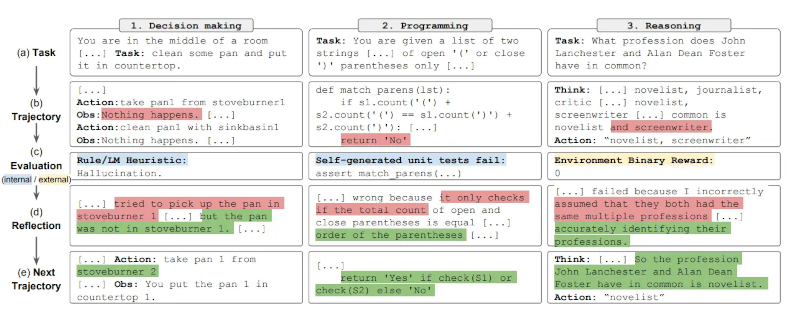
Tóm lại, các bước chính của quy trình Reflexion là a) xác định một nhiệm vụ, b) tạo một quỹ đạo, c) đánh giá, d) thực hiện phản ánh, và e) tạo quỹ đạo tiếp theo. Hình dưới đây minh họa các ví dụ về cách một tác nhân Reflexion có thể học cách tối ưu hóa hành vi của mình theo từng bước lặp để giải quyết các nhiệm vụ khác nhau như ra quyết định, lập trình và suy luận. Reflexion mở rộng khuôn khổ ReAct bằng cách giới thiệu các thành phần tự đánh giá, tự phản ánh và bộ nhớ.
Kết quả
Kết quả thử nghiệm chứng minh rằng các tác nhân Reflexion cải thiện đáng kể hiệu suất trong các tác vụ ra quyết định AlfWorld, các câu hỏi suy luận trong HotPotQA và các tác vụ lập trình Python trên HumanEval.
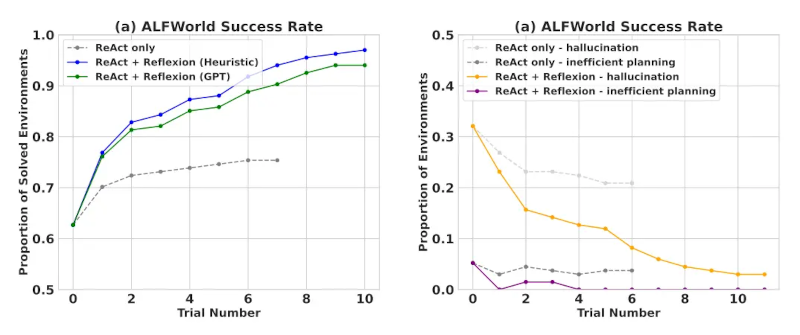
Khi được đánh giá trên các tác vụ ra quyết định tuần tự (AlfWorld), ReAct + Reflexion vượt trội hơn đáng kể so với ReAct khi hoàn thành 130/134 tác vụ bằng các kỹ thuật tự đánh giá Heuristic và GPT để phân loại nhị phân.
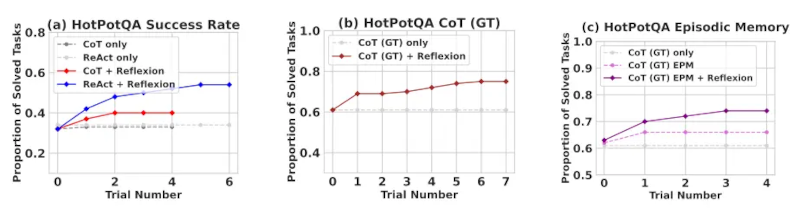
Reflexion vượt trội hơn hẳn so với tất cả các phương pháp cơ bản qua nhiều bước học. Chỉ áp dụng cho suy luận và khi thêm bộ nhớ theo giai đoạn bao gồm quỹ đạo gần nhất, Reflexion + CoT vượt trội hơn so với việc chỉ áp dụng CoT và CoT kết hợp với bộ nhớ theo giai đoạn.
Như tóm tắt trong bảng dưới đây, Reflexion nhìn chung vượt trội hơn các phương pháp tiên tiến trước đây về viết mã Python và Rust trên MBPP, HumanEval và Leetcode Hard.

Khi nào sử dụng Reflexion?
Reflexion phù hợp nhất cho các trường hợp sau:
Tác nhân cần học hỏi từ quá trình thử và sai: Reflexion được thiết kế để giúp tác nhân cải thiện hiệu suất bằng cách suy ngẫm về những sai lầm trong quá khứ và kết hợp kiến thức đó vào các quyết định trong tương lai. Điều này làm cho nó phù hợp với các nhiệm vụ mà tác nhân cần học hỏi thông qua quá trình thử và sai, chẳng hạn như ra quyết định, suy luận và lập trình.
Các phương pháp học tăng cường - RL (Reinforcement Learning) truyền thống không thực tế: Các phương pháp học tăng cường (RL) truyền thống thường yêu cầu dữ liệu huấn luyện phong phú và tinh chỉnh mô hình tốn kém. Reflexion cung cấp một giải pháp thay thế nhẹ nhàng, không yêu cầu tinh chỉnh mô hình ngôn ngữ cơ bản, giúp nó hiệu quả hơn về mặt dữ liệu và tài nguyên tính toán.
Cần có phản hồi có sắc thái: Reflexion sử dụng phản hồi bằng lời nói, có thể có sắc thái và cụ thể hơn so với phần thưởng vô hướng được sử dụng trong RL truyền thống. Điều này cho phép tác nhân hiểu rõ hơn về những sai lầm của mình và thực hiện các cải tiến có mục tiêu hơn trong các lần thử tiếp theo.
Khả năng diễn giải và trí nhớ rõ ràng rất quan trọng: Reflexion cung cấp một dạng trí nhớ theo giai đoạn dễ diễn giải và rõ ràng hơn so với các phương pháp RL truyền thống. Quá trình tự phản ánh của tác nhân được lưu trữ trong bộ nhớ, cho phép phân tích và hiểu rõ hơn về quá trình học tập của nó.
Reflexion hiệu quả trong các tác vụ sau:
Ra quyết định tuần tự: Các tác nhân Reflexion cải thiện hiệu suất của chúng trong các tác vụ AlfWorld, bao gồm việc điều hướng qua nhiều môi trường khác nhau và hoàn thành các mục tiêu nhiều bước.
Suy luận: Reflexion đã cải thiện hiệu suất của các tác nhân trên HotPotQA, một tập dữ liệu trả lời câu hỏi yêu cầu suy luận trên nhiều tài liệu.
Lập trình: Các tác nhân Reflexion viết mã tốt hơn trên các điểm chuẩn như HumanEval và MBPP, đạt được kết quả tiên tiến trong một số trường hợp.
Dưới đây là một số hạn chế của Reflexion:
Dựa vào khả năng tự đánh giá: Reflexion dựa vào khả năng của tác nhân trong việc đánh giá chính xác hiệu suất của nó và tạo ra các phản ánh tự phản ánh hữu ích. Điều này có thể là một thách thức, đặc biệt là đối với các tác vụ phức tạp, nhưng dự kiến Reflexion sẽ ngày càng tốt hơn theo thời gian khi các mô hình tiếp tục cải thiện khả năng.
Hạn chế về bộ nhớ dài hạn: Reflexion sử dụng cửa sổ trượt với dung lượng tối đa, nhưng đối với các tác vụ phức tạp hơn, việc sử dụng các cấu trúc nâng cao như nhúng vector hoặc cơ sở dữ liệu SQL có thể mang lại lợi thế.
Hạn chế về tạo mã: Phát triển hướng kiểm thử có những hạn chế trong việc chỉ định các ánh xạ đầu vào-đầu ra chính xác (ví dụ: hàm tạo không xác định và đầu ra hàm bị ảnh hưởng bởi phần cứng).
Nguồn hình ảnh: Reflexion: Tác nhân Ngôn ngữ với Học Tăng cường Bằng Lời
Tài liệu tham khảo
Về ‘Kỹ thuật viết lời nhắc’ ………. Phần trước ………. Phần tiếp theo
Reflexion is a framework to reinforce language-based agents through linguistic feedback. According to Shinn et al. (2023), "Reflexion is a new paradigm for ‘verbal‘ reinforcement that parameterizes a policy as an agent’s memory encoding paired with a choice of LLM parameters."
At a high level, Reflexion converts feedback (either free-form language or scalar) from the environment into linguistic feedback, also referred to as self-reflection, which is provided as context for an LLM agent in the next episode. This helps the agent rapidly and effectively learn from prior mistakes leading to performance improvements on many advanced tasks.
As shown in the figure above, Reflexion consists of three distinct models:
An Actor: Generates text and actions based on the state observations. The Actor takes an action in an environment and receives an observation which results in a trajectory. Chain-of-Thought (CoT) and ReAct are used as Actor models. A memory component is also added to provide additional context to the agent.
An Evaluator: Scores outputs produced by the Actor. Concretely, it takes as input a generated trajectory (also denoted as short-term memory) and outputs a reward score. Different reward functions are used depending on the task (LLMs and rule-based heuristics are used for decision-making tasks).
Self-Reflection: Generates verbal reinforcement cues to assist the Actor in self-improvement. This role is achieved by an LLM and provides valuable feedback for future trials. To generate specific and relevant feedback, which is also stored in memory, the self-reflection model makes use of the reward signal, the current trajectory, and its persistent memory. These experiences (stored in long-term memory) are leveraged by the agent to rapidly improve decision-making.
In summary, the key steps of the Reflexion process are a) define a task, b) generate a trajectory, c) evaluate, d) perform reflection, and e) generate the next trajectory. The figure below demonstrates examples of how a Reflexion agent can learn to iteratively optimize its behavior to solve various tasks such as decision-making, programming, and reasoning. Reflexion extends the ReAct framework by introducing self-evaluation, self-reflection and memory components.
Experimental results demonstrate that Reflexion agents significantly improve performance on decision-making AlfWorld tasks, reasoning questions in HotPotQA, and Python programming tasks on HumanEval.
When evaluated on sequential decision-making (AlfWorld) tasks, ReAct + Reflexion significantly outperforms ReAct by completing 130/134 tasks using self-evaluation techniques of Heuristic and GPT for binary classification.
Reflexion significantly outperforms all baseline approaches over several learning steps. For reasoning only and when adding an episodic memory consisting of the most recent trajectory, Reflexion + CoT outperforms CoT only and CoT with episodic memory, respectively.
As summarized in the table below, Reflexion generally outperforms the previous state-of-the-art approaches on Python and Rust code writing on MBPP, HumanEval, and Leetcode Hard.
Reflexion is best suited for the following:
An agent needs to learn from trial and error: Reflexion is designed to help agents improve their performance by reflecting on past mistakes and incorporating that knowledge into future decisions. This makes it well-suited for tasks where the agent needs to learn through trial and error, such as decision-making, reasoning, and programming.
Traditional reinforcement learning methods are impractical: Traditional reinforcement learning (RL) methods often require extensive training data and expensive model fine-tuning. Reflexion offers a lightweight alternative that doesn't require fine-tuning the underlying language model, making it more efficient in terms of data and compute resources.
Nuanced feedback is required: Reflexion utilizes verbal feedback, which can be more nuanced and specific than scalar rewards used in traditional RL. This allows the agent to better understand its mistakes and make more targeted improvements in subsequent trials.
Interpretability and explicit memory are important: Reflexion provides a more interpretable and explicit form of episodic memory compared to traditional RL methods. The agent's self-reflections are stored in its memory, allowing for easier analysis and understanding of its learning process.
Reflexion is effective in the following tasks:
Sequential decision-making: Reflexion agents improve their performance in AlfWorld tasks, which involve navigating through various environments and completing multi-step objectives.
Reasoning: Reflexion improved the performance of agents on HotPotQA, a question-answering dataset that requires reasoning over multiple documents.
Programming: Reflexion agents write better code on benchmarks like HumanEval and MBPP, achieving state-of-the-art results in some cases.
Here are some limitations of Reflexion:
Reliance on self-evaluation capabilities: Reflexion relies on the agent's ability to accurately evaluate its performance and generate useful self-reflections. This can be challenging, especially for complex tasks but it's expected that Reflexion gets better over time as models keep improving in capabilities.
Long-term memory constraints: Reflexion makes use of a sliding window with maximum capacity but for more complex tasks it may be advantageous to use advanced structures such as vector embedding or SQL databases.
Code generation limitations: There are limitations to test-driven development in specifying accurate input-output mappings (e.g., non-deterministic generator function and function outputs influenced by hardware).
Figures source: Reflexion: Language Agents with Verbal Reinforcement Learning
Dịch: Lê Trung Nghĩa
letrungnghia.foss@gmail.com
Tác giả: Nghĩa Lê Trung
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Blog này được chuyển đổi từ http://blog.yahoo.com/letrungnghia trên Yahoo Blog sang sử dụng NukeViet sau khi Yahoo Blog đóng cửa tại Việt Nam ngày 17/01/2013.Kể từ ngày 07/02/2013, thông tin trên Blog được cập nhật tiếp tục trở lại với sự hỗ trợ kỹ thuật và đặt chỗ hosting của nhóm phát triển...
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
 ‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
 Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
 12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
 Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
 Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 ‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
 ‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
 Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Tài nguyên Giáo dục Mở trong kỷ nguyên AI
 cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
 Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
 Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025
Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025

