 Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam

Automatic Prompt Engineer (APE)
Theo: https://www.promptingguide.ai/techniques/ape
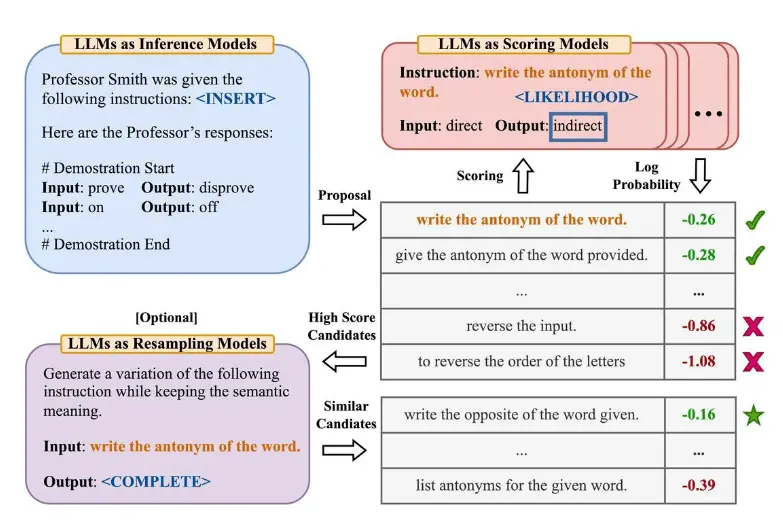
Image Source: Zhou et al., (2022)
Zhou và cộng sự (2022) đề xuất cho các kỹ sư nhắc tự động - APE (Automatic Prompt Engineer) một khuôn khổ cho việc tạo sinh và lựa chọn lệnh tự động. Bài toán tạo sinh lệnh được định hình như tổng hợp ngôn ngữ tự nhiên, được giải quyết như một bài toán tối ưu hóa hộp đen sử dụng LLM để tạo sinh và tìm kiếm các giải pháp ứng viên.
Bước đầu tiên bao gồm một mô hình ngôn ngữ lớn (như một mô hình suy luận) được cung cấp các minh họa đầu ra để tạo sinh các ứng viên lệnh cho một tác vụ. Các giải pháp ứng viên này sẽ hướng dẫn quy trình tìm kiếm. Các lệnh được thực thi bằng cách sử dụng một mô hình mục tiêu, và sau đó lệnh phù hợp nhất được chọn dựa trên điểm đánh giá được tính toán.
APE phát hiện ra một lời nhắc theo chuỗi tư duy (CoT) không có ví dụ/minh họa (zero-shot) tốt hơn lời nhắc "Hãy suy nghĩ từng bước" do con người thiết kế (Kojima và cộng sự, 2022).
Lời nhắc "Hãy giải quyết vấn đề này theo cách từng bước để đảm bảo chúng ta có câu trả lời đúng." gợi ra suy luận chuỗi tư duy và cải thiện hiệu suất trên các điểm chuẩn MultiArith và GSM8K:
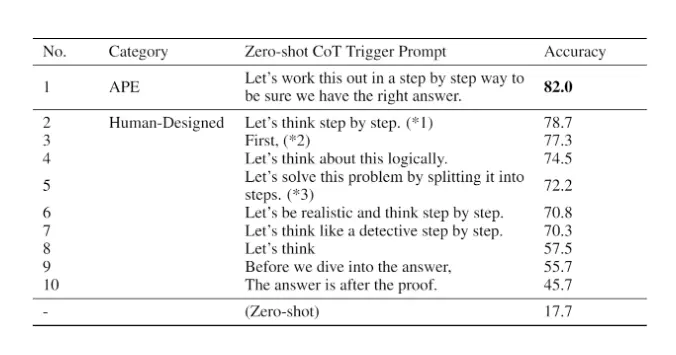
Image Source: Zhou et al., (2022)
Bài báo này đề cập đến một chủ đề quan trọng liên quan đến kỹ thuật nhắc, đó là ý tưởng tự động tối ưu hóa các lời nhắc. Mặc dù chúng tôi không đi sâu vào chủ đề này trong hướng dẫn này, nhưng sau đây là một vài bài báo chính nếu bạn quan tâm đến chủ đề này:
Prompt-OIRL - đề xuất sử dụng học tăng cường ngược ngoại tuyến để tạo ra các lời nhắc phụ thuộc vào truy vấn.
OPRO - giới thiệu ý tưởng sử dụng LLM để tối ưu hóa các lời nhắc: cho phép LLM "Hít một hơi thật sâu" để cải thiện hiệu suất xử lý các bài toán.
AutoPrompt - đề xuất một phương pháp tự động tạo các lời nhắc cho một tập hợp các tác vụ đa dạng dựa trên tìm kiếm theo hướng gradient.
Prefix Tuning - một giải pháp thay thế nhẹ cho việc tinh chỉnh, thêm một tiền tố liên tục có thể huấn luyện được cho các tác vụ NLG.
Prompt Tuning - đề xuất một cơ chế để học các lời nhắc mềm thông qua lan truyền ngược.
Về ‘Kỹ thuật viết lời nhắc’ ………. Phần trước ………. Phần tiếp theo
Zhou et al., (2022) propose automatic prompt engineer (APE) a framework for automatic instruction generation and selection. The instruction generation problem is framed as natural language synthesis addressed as a black-box optimization problem using LLMs to generate and search over candidate solutions.
The first step involves a large language model (as an inference model) that is given output demonstrations to generate instruction candidates for a task. These candidate solutions will guide the search procedure. The instructions are executed using a target model, and then the most appropriate instruction is selected based on computed evaluation scores.
APE discovers a better zero-shot CoT prompt than the human engineered "Let's think step by step" prompt (Kojima et al., 2022).
The prompt "Let's work this out in a step by step way to be sure we have the right answer." elicits chain-of-thought reasoning and improves performance on the MultiArith and GSM8K benchmarks:
This paper touches on an important topic related to prompt engineering which is the idea of automatically optimizing prompts. While we don't go deep into this topic in this guide, here are a few key papers if you are interested in the topic:
Prompt-OIRL - proposes to use offline inverse reinforcement learning to generate query-dependent prompts.
OPRO - introduces the idea of using LLMs to optimize prompts: let LLMs "Take a deep breath" improves the performance on math problems.
AutoPrompt - proposes an approach to automatically create prompts for a diverse set of tasks based on gradient-guided search.
Prefix Tuning - a lightweight alternative to fine-tuning that prepends a trainable continuous prefix for NLG tasks.
Prompt Tuning - proposes a mechanism for learning soft prompts through backpropagation.
Dịch: Lê Trung Nghĩa
letrungnghia.foss@gmail.com
Tác giả: Nghĩa Lê Trung
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Blog này được chuyển đổi từ http://blog.yahoo.com/letrungnghia trên Yahoo Blog sang sử dụng NukeViet sau khi Yahoo Blog đóng cửa tại Việt Nam ngày 17/01/2013.Kể từ ngày 07/02/2013, thông tin trên Blog được cập nhật tiếp tục trở lại với sự hỗ trợ kỹ thuật và đặt chỗ hosting của nhóm phát triển...
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
 ‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
 Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
 12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
 Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
 Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 ‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
 ‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
 Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Tài nguyên Giáo dục Mở trong kỷ nguyên AI
 cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
 Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
 Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025
Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025

