 Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam

Digital transformation and persistent identifiers for digital objects in higher education institutions
***
Tóm tắt: Ngày nay, mã nhận diện thường trực thường được sử dụng để quản lý các đối tượng kỹ thuật số. Bài viết này gợi ý rằng các tổ chức giáo dục đại học, cũng như các thư viện, giáo viên và nhà nghiên cứu của họ cũng nên làm như vậy.
Các từ khóa: mã nhận diện thường trực (PID), mã nhận diện đối tượng số (DOI), mã nhận diện người đóng góp và nhà nghiên cứu mở (ORCID), đăng ký tổ chức nghiên cứu (ROR).
Abstract: Nowadays, persistent identifiers are commonly used to manage digital objects. This article suggests that Higher Education istitutions, as well as their libraries, teachers and researchers, should do the same.
Keywords: Persistent IDentifiers (PID), Digital Object Identifiers (DOI), Open Researcher and Contributor IDentifier (ORCID), Research Organization Registry (ROR).
***
1. Đặt vấn đề
Để vận hành môi trường nghiên cứu FAIR trong bối cảnh chuyển đổi số và chuyển đổi sang khoa học mở, như được nhắc lại nhiều lần trong tài liệu Khuyến nghị Khoa học Mở của UNESCO 2021[1], một trong những điều không thể thiếu, trong vô số việc phải làm khác, là ứng dụng và phát triển hệ thống mã nhận diện thường trực - PID (Persistent IDentifier), trong đó có dịch vụ gắn PID cho nhiều đối tượng khác nhau, bao gồm nhưng không bị hạn chế tới chỉ dữ liệu/siêu dữ liệu, các nhà nghiên cứu và những người đóng góp cho nghiên cứu, các cơ sở giáo dục đào tạo/các viện nghiên cứu, và các đối tượng khác, đặc biệt là các đối tượng số.
2. Định nghĩa FAIR, PID và hệ thống PID
Định nghĩa FAIR. Trong phần lời nói đầu khi giới thiệu các nguyên tắc dữ liệu FAIR của FORCE11[2], một cộng đồng các học giả, thủ thư, nhân viên lưu trữ, nhà xuất bản và nhà cấp vốn nghiên cứu được hình thành để giúp tạo điều kiện thuận lợi cho sự thay đổi hướng tới việc tạo lập và chia sẻ kiến thức được cải thiện, có đoạn giới thiệu FAIR như sau:
“Một trong những thách thức lớn của khoa học tăng cường dữ liệu là tạo thuận lợi cho việc phát hiện tri thức bằng cách hỗ trợ cho cả con người và máy trong khám phá, truy cập, tích hợp và phân tích dữ liệu khoa học phù hợp nhiệm vụ và các thuật toán/các tiến trình có liên quan. Ở đây, chúng tôi mô tả FAIR - một tập hợp các nguyên tắc làm cho dữ liệu Tìm thấy được, Truy cập được, Tương hợp được, và Sử dụng lại được - FAIR (Findable, Accessible, Interoperable, Reusable).”

Hình 1. Các nguyên tắc dữ liệu FAIR
Định nghĩa ở trên cho thấy, để các nguyên tắc dữ liệu FAIR hoạt động được, điều kiện tiên quyết là phải sử dụng các mã nhận diện thường trực - PID (Persistent Identifiers). FORCE11 cũng chỉ ra rằng, trên thực tế, nếu dữ liệu/siêu dữ liệu không được gắn PID, thì dữ liệu đó hầu như không sử dụng lại được (tới 80%)[3] - điều hoàn toàn trái ngược với các nguyên tắc dữ liệu FAIR.
Định nghĩa PID. Tài liệu của Knowledge Exchange định nghĩa PID[4]:
“Các PID như là các mã nhận diện có thể được gắn cho bất kỳ dạng đối tượng nào (vật lý hoặc số). Chúng hầu hết đang được gắn cho con người, các tổ chức, và kết quả đầu ra nghiên cứu. Các mục đích của chúng (ngoài việc nhận diện thường trực) là để cải thiện quản lý và truy xuất thông tin nghiên cứu.”
PID có 3 đặc tính là:
duy nhất trên toàn cầu, bao gồm cú pháp và không gian tên được kiểm soát, được các cơ quan có thẩm quyền được xác định rõ ràng điều hành quản lý;
thường trực, bao gồm các chức năng liên kết và phân giải thường trực và ổn định, cú pháp và các lược đồ thường trực, các đối tượng được tham chiếu thường trực;
phân giải được cho cả con người và máy móc, bao gồm thông tin về làm thế nào đối tượng được tham chiếu có thể tìm thấy được, truy cập được, hoặc sử dụng được sẽ được tìm ra.

Hình 2. Dữ liệu/siêu dữ liệu sẽ không sử dụng lại được nếu không có PID
Định nghĩa Hệ thống PID:
“Một hệ thống PID như một tổng thể được coi là sự kết hợp được tham chiếu lẫn nhau của các định nghĩa, chính sách, dịch vụ và nguồn dữ liệu được sử dụng cho việc quản trị và sử dụng các PID. Ngay cả khi các PID chủ yếu được yêu cầu để quản lý thông tin nghiên cứu, chúng cũng nên giảm bớt gánh nặng cho cá nhân nhà nghiên cứu. Giá trị gia tăng này được minh họa rõ ràng bằng khái niệm Biểu đồ PID (PID Graph) (xem Hình 3), liên quan đến các mối quan hệ liên kết và ngữ nghĩa giữa các thực thể mà PID đã được gắn vào, chẳng hạn như con người (các nhà nghiên cứu), các tổ chức, các xuất bản phẩm nghiên cứu, dữ liệu nghiên cứu, việc cấp vốn và các kết quả nghiên cứu khác.”
Biểu đồ trên Hình 3 là lý tưởng, khi các PID được gắn cho con người, xuất bản phẩm, dữ liệu, tổ chức, nhà cấp vốn, và phần mềm được kết nối lẫn nhau, tương hợp được với nhau, vừa giúp quản trị và sử dụng các PID, vừa tạo ra giá trị gia tăng để làm giảm bớt gánh nặng cho các nhà nghiên cứu, dù trên thực tế, hiện nó mới ở mức rất sơ khai và có lẽ còn rất lâu nữa mới có thể hiện thực hóa được nó đạt mức tới hạn đủ lớn và mức phổ cập sau đó.
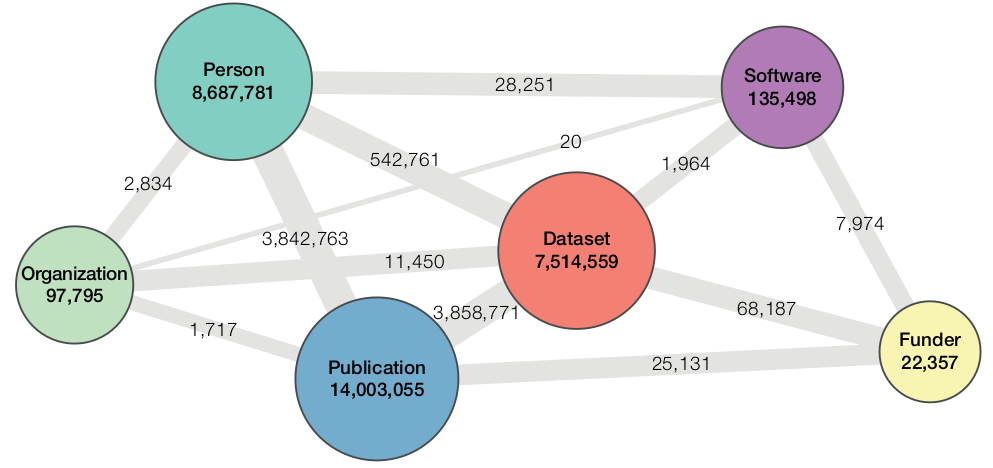
Hình 3. Biểu đồ PID của Datacite
Hệ thống các PID được coi là hạ tầng không thể thiếu của nghiên cứu khoa học ngày nay. Ở thời điểm hiện tại, hệ thống các PID này đang bị phân mảnh, chưa có được sự kết nối lẫn nhau cũng như tính tương hợp như mong muốn. Điều này được giải thích là vì các PID và hệ thống PID không đơn giản là một hệ thống thuần túy kỹ thuật, mà nó là một hệ thống kỹ thuật - xã hội, dựa vào lòng tin và rủi ro ở 4 khía cạnh: chính trị, kinh tế, xã hội và công nghệ. Để có được lòng tin và độ tin cậy cần thiết, hệ thống/hạ tầng PID cần phải được xây dựng dựa vào tính mở, bao trùm cả hai khía cạnh, tính mở kỹ thuật theo nghĩa của khả năng kết nối và tính tương hợp, và tính sẵn sàng mở của dữ liệu và siêu dữ liệu. Nguồn mở và dữ liệu mở được coi là tính năng chính cho lòng tin và độ tin cậy. Theo ngữ cảnh của khoa học mở thì hệ thống/hạ tầng PID có thể được coi như là hàng hóa công cộng, và vì thế nên được cộng đồng sở hữu và do cộng đồng điều hành. Tuy nhiên, đây là những vấn đề không được phân tích sâu ở đây, vì chúng không nằm trong phạm vi của bài viết này.
3. Hệ sinh thái PID, phân loại PID và các PID được ưu tiên sử dụng hiện nay
Các tác nhân khác nhau với các vai trò khác nhau trong hệ sinh thái PID[5], gồm:
Cơ quan có thẩm quyền về PID. Một nhà kiểm soát có trách nhiệm duy trì các quy định để xác định tính toàn vẹn và tính duy nhất của các PID trong hệ thống PID.
Nhà cung cấp dịch vụ PID. Một tổ chức cung cấp các dịch vụ PID tuân thủ với một hệ thống PID, tuân theo cơ quan PID của nó. Các nhà cung cấp dịch vụ PID có trách nhiệm về cung cấp, tính toàn vẹn, độ tin cậy và khả năng mở rộng phạm vi các dịch vụ PID, đặc biệt việc ban hành và phân giải các PID, mà còn cả các dịch vụ tra cứu và tìm kiếm nữa.
Nhà quản lý PID. Các nhà quản lý PID có trách nhiệm duy trì tính toàn vẹn của mối quan hệ giữa các thực thể và các PID của họ, tuân thủ với một hệ thống PID được cơ quan PID xác định. Một nhà quản lý PID thường sẽ thuê bao các dịch vụ PID để cung cấp chức năng cho chủ sở hữu PID trong các dịch vụ của nhà quản lý PID đó.
Chủ sở hữu PID. Một tác nhân (một tổ chức hoặc cá nhân) có quyền tạo lập một PID, chỉ định PID cho một thực thể, cung cấp và duy trì thông tin hạt nhân (Kernel Information) chính xác bao gồm vị trí cho PID đó. Chủ sở hữu PID là chủ sở hữu của bản ghi PID cá nhân.
Người sử dụng đầu cuối. Người sử dụng đầu cuối các dịch vụ PID và các dịch vụ của người sử dụng PID. Chúng có thể, ví dụ là, các nhà nghiên cứu, hoặc phần mềm, hoặc các dịch vụ được sản xuất để hỗ trợ cho các nhà nghiên cứu. Những người sử dụng đầu cuối sẽ sử dụng các PID để trích dẫn và truy cập các tài nguyên hoặc thông tin hạt nhân về các tài nguyên đó.
Các tác nhân được nêu ở đây là thường thấy ở mức quốc gia. Tuy nhiên, như ở trên đã nêu, 1 trong 3 đặc tính của PID là ‘duy nhất trên toàn cầu’ nên các tác nhân ở mức toàn cầu trong hệ sinh thái PID có thể sẽ khác một chút.
Định nghĩa hệ thống PID và biểu đồ PID của Datacite ở trên cho thấy, có nhiều loại PID khác nhau được gắn cho các thực thể và/hoặc đối tượng khác nhau. Thông qua các tài liệu nghiên cứu, có thể chỉ ra các loại PID khác nhau và các PID hiện đang được ưu tiên sử dụng như bên dưới đây.
Các PID có thể được phân loại theo:
Các PID được thiết lập tốt. Một số mã nhận diện đang được các tổ chức khắp trên thế giới sử dụng rồi, chẳng hạn, ARK, DOI, Handles, URN phân giải cho dữ liệu và các xuất bản phẩm, còn ISNI, ORCID thì trỏ tới thông tin xác thực về các cá nhân
Các PID nội tại. Các PID này thường do chủ sở hữu PID hoặc nhà cung cấp PID quản lý. Ví dụ điển hình là SWHID do kho lưu trữ Di sản Phần mềm (Software Heritage - https://www.softwareheritage.org/) phát hành miễn phí tại: https://docs.softwareheritage.org/devel/swh-model/persistent-identifiers.html. Ví dụ khác là mã nội dung ISCC (https://iscc.codes/) cũng phát hành miễn phí cho bất kỳ tệp kỹ thuật số các dạng đa phương tiện chung nào (văn bản, hình ảnh, âm thanh, video).
Các PID tự quản và các PID phi tập trung. Nhận diện tự quản (Self-sovereign identity) là “hệ thống quản lý nhận diện cho phép các cá nhân sở hữu và quản lý hoàn toàn nhận diện số của họ” mà tồn tại độc lập với các dịch vụ, ví dụ, Facebook, Google hoặc bất kỳ dịch vụ nào khác yêu cầu một cá nhân đăng nhập.
Các PID cũng có thể được phân loại theo một cách khác dựa vào thực tế ứng dụng và phát triển hiện nay trên thế giới, chẳng hạn như:
PID cho các đối tượng số DOI, thường được sử dụng cho các kết quả đầu ra nghiên cứu ở dạng kỹ thuật số.
PID cho các cá nhân như ORCID và/hoặc ResearcherID. Chúng thường được sử dụng cho các nhà nghiên cứu và những người đóng góp cho nghiên cứu.
PID cho các tổ chức, ví dụ như OrgID[6] và/hoặc đăng ký tổ chức nghiên cứu – ROR (Research Organization Registry). Hiện đang có nhu cầu cao về các PID này nên bao trùm cả các tổ chức trực thuộc bên trong một tổ chức.
PID cho các dịch vụ tác giả của tài liệu nghiên cứu về kinh tế - RAS (RePEc Author Service)[7], trong đó RePEc (Research Papers in Economics) có nghĩa là các tài liệu nghiên cứu về kinh tế.
Số Mẫu Chung Quốc tế - IGSN (International Generic Sample Number)[8] ban đầu từng là mã nhận diện thường trực cho các đối tượng (mẫu) vật lý, thường được sử dụng trong lĩnh vực địa lý, địa chất khoáng sản, .v.v.
PID cho các công cụ và tiện ích nghiên cứu PIDINST[9].
Và nhiều loại PID đang được phát triển và mới nổi lên khác. Cũng đã có ví dụ về việc PID mức quốc gia dù đã được phát triển tốt đã bị/được thay thế bằng PID mức quốc tế, như trong trường hợp mã tác giả số – DAI (Digital Author Identifier)[10] của Hà Lan đã bị/được thay thế bằng các mã nhận diện mức quốc tế ORCID/ISNI.
Trên thực tế, có hàng chục loại PID khác nhau nằm trong cả 3 phân loại PID này, trong đó có DOI (nơi có chấm đỏ), như được minh họa trên Hình 4.
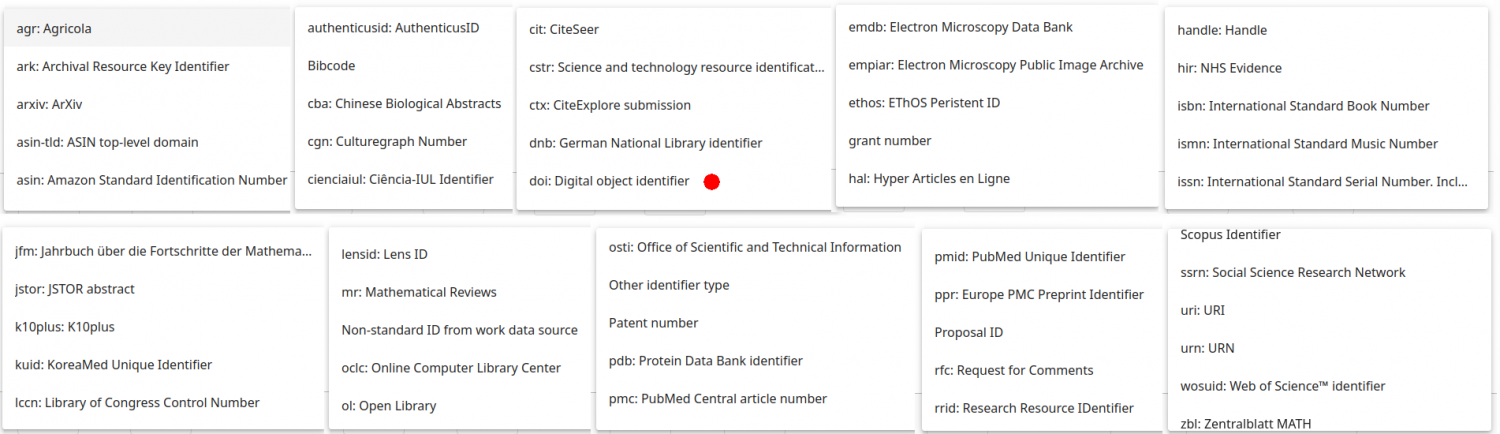
Hình 4. Vài chục loại PID có thể được chọn khi sử dụng ORCID
Tuy nhiên, để các PID có thể kết nối lẫn nhau và tương hợp được với nhau ở mức toàn cầu nhằm hiện thực hóa các nguyên tắc FAIR, chỉ một số ít các PID được khuyến nghị sử dụng ở thời điểm hiện nay.
Một dự án nghiên cứu khảo sát[11] được tiến hành ở Vương quốc Anh vào năm 2020 với mục đích điều tra các mức nhận thức, áp dụng và tích hợp PID vào các hệ thống nghiên cứu chủ chốt ở quốc gia này. Dự án dựa vào một loạt các PID ‘ưu tiên’ cụ thể cho nghiên cứu mở. Chúng là các PID cho các trợ cấp (các mã nhận diện Đối tượng Số - DOI, do Crossref cung cấp), cho các tổ chức (mã nhận diện Đăng ký Tổ chức Nghiên cứu - ROR), cho các kết quả đầu ra (các mã nhận diện Đối tượng Số - DOI, do Crossref và DataCite cung cấp), cho con người (Mã nhận diện Người đóng góp và Nhà nghiên cứu Mở - ORCID), và cho các dự án (Mã nhận diện Hoạt động Nghiên cứu - RAiD, do Research Data Commons của Úc cung cấp).
Tham gia khảo sát có 93 người, trong đó có 67 người (71%) làm việc trong các trường đại học hoặc viện nghiên cứu. Trả lời cho câu hỏi khảo sát: Các PID nào sau đây hiện bạn đang sử dụng hoặc có kế hoạch sử dụng trong các tổ chức của bạn? Những người trả lời đã đưa ra nhiều loại PID khác nhau, bao gồm cả 5 loại PID được ưu tiên vừa được nêu ở trên, như được minh họa trên Hình 5, với xếp hạng theo trật tự được sử dụng nhiều nhất từ trên xuống cho 5 loại PID là: (1) DOI; (2) ORCID; (3) ROR; (4) ISNI; và (5) RAiD. Kết quả cũng cho thấy, với hai loại PID được sử dụng nhiều nhất là DOI (94%) và ORCID (90%), bỏ xa các loại PID còn lại.

Hình 5. Các PID hoặc đang hoặc có kế hoạch được sử dụng trong các tổ chức
Tương tự, mức độ thỏa mãn nhiều nhất khi sử dụng các PID cũng được dành cho 5 loại PID này, nhưng với trật tự có một chút thay đổi, dù 2 vị trí đầu tiên vẫn được giữ nguyên dành cho (1) DOI (90%) và (2) ORCID (72%), như trên Hình 6.
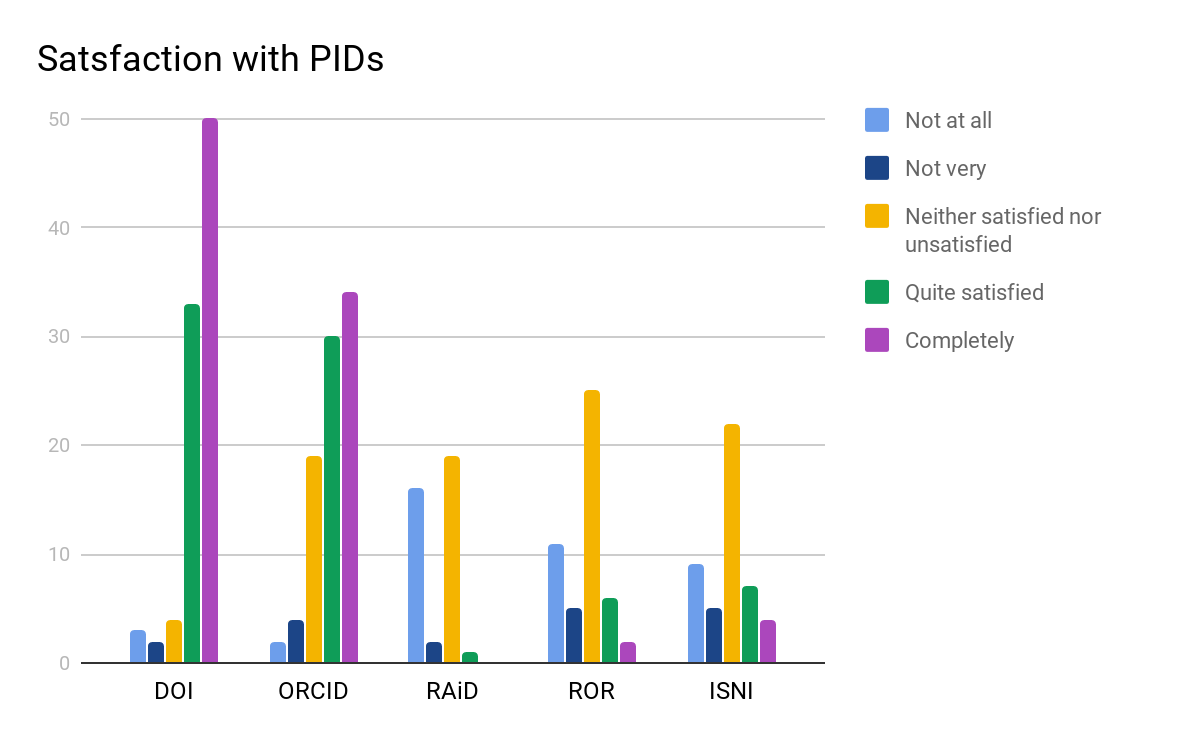
Hình 6. Các mức thỏa mãn với các PID
4. Tích hợp DOI và ORCID, một ví dụ tích hợp các PID trong thực tế
Chương trình Chuyển đổi sang Khoa học Mở TOPS (Transform to Open Science) của Cơ quan Hàng không Vũ trụ Mỹ NASA nhân sự kiện năm 2023 là năm Khoa học Mở ở nước Mỹ, đã đưa ra ‘Hướng dẫn lộ trình Khoa học Mở cho bạn’[12] với mục đích để bất kỳ ai cũng có thể bắt đầu tham gia vào khoa học mở bắt đầu bằng việc xây dựng cho bản thân mình các năng lực cốt lõi của khoa học mở, trong đó có việc: (1) biết sử dụng ORCID, Zenodo, GitHub; và (2) biết cách gắn mã nhận diện đối tượng số (DOI) cho kết quả nghiên cứu, ví dụ như một bài báo, cuốn sách, tài liệu dịch .v.v.; và vài năng lực cốt lõi khác.
Hình 7 và 8 bên dưới là ví dụ trình bày kết quả của việc sử dụng và tích hợp giữa ORCID và DOI (trên Zenodo), và là bước khởi đầu để có được một vài năng lực cốt lõi của khoa học mở, cũng vừa là bước khởi đầu để hiện thực hóa biểu đồ PID của DataCite như ở Hình 3 bên trên, bằng việc sử dụng một ORCID cho tác giả và gắn DOI cho bài tham luận được trình bày tại các hội thảo và được tải lên Zenodo.
Như trên Hình 7, bài tham luận có 2 phiên bản đều ở dạng tệp PDF và đều đã được tải lên Zenodo, với mã DOI: 10.5281/zenodo.7963261 cho phiên bản 1 (Version V1.0), mã DOI: 10.5281/zenodo.7976278 cho phiên bản 2 (Version V2.0) và mã DOI: 10.5281/zenodo.7963260 chung cho cả 2 phiên bản đó (Concept DOI).

Hình 7. Các DOI cho 2 phiên bản của cùng một tài liệu trên Zenodo
Trong khi đó trên Hình 8, là một phần của màn hình ORCID cho người sử dụng, cũng cho thấy chính xác đủ cả 3 mã DOI y hệt đó.
Hình 8. Các DOI trên Zenodo được tích hợp với ORCID của cùng một tài liệu
Với việc tích hợp ORCID và DOI (trên Zenodo), người sử dụng ORCID (Hình 8), một mặt, có thể nhấn vào các đường link của từng phiên bản DOI để đến với phiên bản tương ứng của tài liệu trước đó đã được tải lên Zenodo để có thể tải về tài liệu đó, xem tất cả các thông tin liên quan tới tài liệu đó đã được tác giả của tài liệu nhập vào Zenodo, ví dụ như, tên tác giả, ngày xuất bản, tiêu đề và mô tả tài liệu, giấy phép của tài liệu, thông tin thừa nhận ghi công cho tác giả, và nhiều thông tin liên quan khác. Mặt khác, người sử dụng ORCID cũng có thể nhấn vào đường link ‘Show more detail’ (Xem chi tiết hơn) ở phía trên bên tay phải phần màn hình ORCID tương ứng với tài liệu đó (Hình 8) để xem chi tiết các thông tin mà tác giả của tài liệu đã nhập vào trong ORCID và cho phép người sử dụng nhìn thấy, bao gồm: (1) các thông tin liên quan tới tác phẩm (2) trích dẫn; (3) các mã nhận diện thường trực; (4) những người đóng góp; (5) các thông tin khác; và (6) khả năng nhìn thấy đối với mọi thông tin tác giả nhập vào. Ngoài các thông tin liên quan tới (các) tác phẩm, bạn cũng có thể nhìn thấy nhiều chủng loại thông tin khác mà tác giả nhập vào ORCID và cho phép bạn nhìn thấy, ví dụ như về: (1) công việc của tác giả; (2) quá trình đào tạo và công tác; (3) vị trí được mời và sự khác biệt; (4) thành viên và dịch vụ; và (5) vốn cấp. Mỗi chủng loại thông tin như vậy sẽ có nhiều trường thông tin liên quan. Ngoài các chủng loại thông tin đó ra, còn có thể có những thông tin khác liên quan tới tác giả, như mã ORCID, các đường liên kết tới các website và mạng xã hội của tác giả, các từ khóa tác giả đặt cho hồ sơ ORCID của mình, và quốc gia xuất thân của tác giả.
Như vậy là, với ORCID được tích hợp với DOI (trên Zenodo) bạn sẽ không chỉ có khả năng quản lý hồ sơ nghiên cứu khoa học của bạn trên ORCID, mà bạn còn có khả năng quản lý được mọi kết quả nghiên cứu của bạn và các thông tin liên quan tới chúng mà bạn đã tải lên và/hoặc nhập vào Zenodo. Có thể điều này cũng sẽ giúp bạn mỗi lần phải viết báo cáo về các sản phẩm là kết quả nghiên cứu của bạn.
Và bạn hãy thử hình dung, nếu việc tích hợp không phải chỉ là giữa ORCID với DOI, mà còn là với cả các PID khác, như trong biểu đồ PID của DataCite ở Hình 3 bên trên, và có thể với các PID khác nữa, thì hồ sơ nghiên cứu của bạn sẽ được quản lý tuyệt vời như thế nào; và chắc chắn, nó sẽ giúp giảm nhẹ gánh nặng của bạn trong công việc báo cáo và nhiều hoạt động nghiên cứu khác nữa, trong khi nhiều nhà nghiên cứu khác có thể hưởng lợi từ việc sử dụng các kết quả nghiên cứu đã được mở ra của bạn, và ngược lại. Đây chính là cách tiếp cận của ‘Hồ sơ Tính mở’ (Openness Profile) trong tương lai của từng nhà nghiên cứu/người đóng góp cho nghiên cứu mà Khoa học Mở đang hướng tới.
5. Kết luận và gợi ý
Ngày nay, hệ thống PID là hạ tầng quan trọng không thể thiếu của nghiên cứu khoa học, đặc biệt trong bối cảnh Khoa học Mở đã trở thành xu thế không thể đảo ngược của thế giới.
Số lượng các PID là rất nhiều và trong số đó vẫn có các PID đang tiến hóa và/hoặc đang nổi lên, bao trùm nhiều ngành, nhiều lĩnh vực, và ở nhiều mức khác nhau. Tuy nhiên, ở thời điểm hiện nay, số lượng các PID được khuyến nghị ưu tiên sử dụng là không nhiều, chúng đều ở mức toàn cầu và tập trung vào các loại PID cho 5 đối tượng sau: (1) các trợ cấp (DOI, do Crossref cung cấp); (2) các kết quả đầu ra nghiên cứu (DOI, do Crossref và DataCite cung cấp); (3) nhà nghiên cứu và người đóng góp cho nghiên cứu (ORCID); (4) các tổ chức (ROR); và (5) các dự án - các hoạt động nghiên cứu (RaiD); trong đó hai đối tượng đầu đều sử dụng mã nhận diện đối tượng số DOI.
Để bước đầu có được các kỹ năng khoa học mở cốt lõi, và quan trọng hơn, để có thể tự quản lý các hoạt động nghiên cứu, tiết kiệm thời gian và gia tăng lòng tin đối với các nhà nghiên cứu và các kết quả đầu ra nghiên cứu của chính mình trong bối cảnh của chuyển đổi số và chuyển đổi sang khoa học mở như hiện nay, cũng như theo đề xuất hướng dẫn lộ trình khoa học mở của NASA, gợi ý các các giảng viên, các nhà nghiên cứu trong các cơ sở giáo dục đại học và các viện nghiên cứu nên sử dụng ORCID để nhận diện duy nhất bản thân ở mức toàn cầu, và DOI cho các kết quả nghiên cứu của mình, rồi tích hợp chúng với nhau, ví dụ như bằng việc sử dụng Zenodo, bằng cách đó tận dụng tối đa sức mạnh của kỹ thuật số theo phương châm ‘nhập liệu một lần, sử dụng lại thường xuyên’, và... miễn phí.
Các cơ sở giáo dục đại học và các viện nghiên cứu, nơi đa số các nhà nghiên cứu làm việc, cũng sẽ hưởng lợi từ việc các nhà nghiên cứu của họ sử dụng các PID như ORCID và DOI, vì nó sẽ giúp quản lý nghiên cứu và các nhà nghiên cứu tốt hơn với các ứng dụng kỹ thuật số theo tiêu chuẩn quốc tế ở mức toàn cầu, hướng tới việc xây dựng Hồ sơ Tính mở với việc tích hợp của nhiều PID khác tương hợp được với nhau trong tương lai, như được minh họa trong biểu đồ PID của Datacite (Hình 3) với mục đích mang lại nhiều lợi ích nhất có thể cho tất cả các bên liên quan tới nghiên cứu khoa học và bản thân khoa học.
Nhu cầu xây dựng các hệ thống PID chắc chắn sẽ gia tăng trong thời gian tới khắp trên thế giới, cả ở mức quốc gia lẫn ở mức cơ sở/tổ chức, và ở Việt Nam có lẽ cũng không là ngoại lệ. Việc một hệ thống PID mức quốc gia hoạt động được cho là tốt như DAI của Hà Lan bị/được thay thế bằng các mã nhận diện mức quốc tế ORCID/ISNI gợi ý rằng, các hệ thống PID mức quốc gia/cơ sở/tổ chức, nếu được xây dựng, phải luôn nghĩ tới việc tuân thủ định nghĩa PID với 3 đặc tính của nó và phải tích hợp được với các hệ thống PID mức quốc tế ngay từ lúc thiết kế ban đầu để tránh lãng phí công sức và các nguồn lực, tránh việc phải ‘Triển khai các PID lỗi và PID không tin cậy’[13] như kinh nghiệm của thế giới đã chỉ ra.
Tài liệu tham khảo
[1] UNESCO, 2021: Recommendation on Open Science: https://unesdoc.unesco.org/ark:/48223/pf0000379949. Bản dịch sang tiếng Việt: https://www.dropbox.com/s/l3q04t99nil5mgo/379949eng_Vi-25112021.pdf?dl=0
[2] FORCE11: The FAIR Data Principles: https://force11.org/info/the-fair-data-principles/.
[3] FORCE11: Guiding Principles for Findable, Accessible, Interoperable and Re-usable Data Publishing version b1.0: https://force11.org/info/guiding-principles-for-findable-accessible-interoperable-and-re-usable-data-publishing-version-b1-0/. Bản tiếng Việt: https://vnfoss.blogspot.com/2017/07/chi-dan-cac-nguyen-tac-xuat-ban-du-lieu.html
[4] Knowledge Exchange (2023): Building the plane as we fly it: the promise of Persistent Identifiers: https://doi.org/10.5281/zenodo.7258286. Bản dịch sang tiếng Việt: https://zenodo.org/record/8102956.
[5] Knowledge Exchange (2021): KE Scoping Document (Version 5.5): Risks and Trust in Pursuit of a Well-functioning Persistent Identifier Infrastructure for Research: https://doi.org/10.5281/zenodo.5018216. Bản tiếng Việt: https://zenodo.org/record/8015888
[6] Knowledge Exchange (2023): The gradual implementation of organisational identifiers (OrgIDs): https://zenodo.org/record/7327535. Bản dịch sang tiếng Việt: https://zenodo.org/record/8057925
[7] Knowledge Exchange (2023): RePEc Author Service: An established community-driven PID: https://doi.org/10.5281/zenodo.7330516. Bản tiếng Việt: https://zenodo.org/record/8072669
[8] Knowledge Exchange (2023): IGSN – building and expanding a community-driven PID system: https://doi.org/10.5281/zenodo.7330498. Bản tiếng Việt: https://zenodo.org/record/8057894
[9] Knowledge Exchange (2023): Persistent identifiers for research instruments and facilities: an emerging PID domain in need of coordination: https://zenodo.org/record/7330372. Bản dịch sang tiếng Việt: https://zenodo.org/record/8057915
[10] Knowledge Exchange (2023): Adoption of the DAI in the Netherlands and subsequent superseding by ORCID/ISNI: https://doi.org/10.5281/zenodo.7327505. Bản dịch sang tiếng Việt: https://zenodo.org/record/8057937
[11] Alice Meadows and Josh Brown for JISC (2020): Persistent identifiers adoption and awareness survey report: https://repository.jisc.ac.uk/8107/1/PIDs%20for%20OA%20project%20community%20survey%20report.pdf. Bản tiếng Việt: https://zenodo.org/record/8105182
[12] NASA: Guide for Your Open Science Journey: https://nasa.github.io/Transform-to-Open-Science-Book/Open_Science_Cookbook/Your_Open_Science_Journey.html. Bản tiếng Việt: https://giaoducmo.avnuc.vn/khoa-hoc-mo/huong-dan-lo-trinh-khoa-hoc-mo-cho-ban-888.html
[13] Knowledge Exchage (2023): Failed PIDs and unreliable PID implementations: https://doi.org/10.5281/zenodo.7330527. Bản tiếng Việt: https://zenodo.org/record/8015956
![]()
Giấy phép nội dung: CC BY 4.0 Quốc tế.
Tự do tải về bài viết định dạng PDF ở địa chỉ DOI: 10.5281/zenodo.10183156
![]() Lê Trung Nghĩa, ORCID iD: https://orcid.org/0009-0007-7683-7703
Lê Trung Nghĩa, ORCID iD: https://orcid.org/0009-0007-7683-7703
Viện Nghiên cứu, Đào tạo và Phát triển Tài nguyên Giáo dục Mở (InOER),
Hiệp hội các trường đại học, cao đẳng Việt Nam (AVU&C)
(Bài viết cho hội thảo ‘Quản trị thông tin trong kỷ nguyên số’ (IMCON2023) do Trường Đại học Văn hóa Hà Nội tổ chức ngày 22/11/2023, được đăng trong Kỷ yếu hội thảo, các trang 210-225)
Xem thêm:
Tác giả: Nghĩa Lê Trung
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Blog này được chuyển đổi từ http://blog.yahoo.com/letrungnghia trên Yahoo Blog sang sử dụng NukeViet sau khi Yahoo Blog đóng cửa tại Việt Nam ngày 17/01/2013.Kể từ ngày 07/02/2013, thông tin trên Blog được cập nhật tiếp tục trở lại với sự hỗ trợ kỹ thuật và đặt chỗ hosting của nhóm phát triển...
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
 ‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
 Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
 12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
 Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
 Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 ‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
 ‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
 cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
 Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
 Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
 Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025
Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025

