 Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam

Lê Trung Nghĩa, ORCID iD: https://orcid.org/0009-0007-7683-7703
Viện Nghiên cứu, Đào tạo và Phát triển Tài nguyên Giáo dục Mở - InOER (Institute for Research, Training and Development of Open Educational Resources),
Hiệp hội các trường đại học cao đẳng Việt Nam (AVU&C)
Giấy phép nội dung: CC BY 4.0 Quốc tế.
***

Tóm tắt: “Không có dữ liệu, không có AI”. AI lấy dữ liệu làm trung tâm (Data-centric AI) với trọng tâm nhằm vào cơ sở hạ tầng dữ liệu của AI - bao gồm các tập dữ liệu, các công cụ, tiêu chuẩn, thực hành, và cộng đồng - đang ngày càng trở nên quan trọng hơn bao giờ hết đối với việc phát triển và ứng dụng AI khắp trên thế giới. Tuy nhiên, hiện đang có nhiều vấn đề liên quan đến dữ liệu, cả kỹ thuật và phi kỹ thuật, cần phải được giải quyết để AI được an toàn, minh bạch, có trách nhiệm và ‘nhân tính’ hơn. Có thể tham khảo 5 khuyến nghị của Viện Dữ liệu Mở (ODI) trong việc giải quyết vấn đề này.
Từ khóa: AI, trí tuệ nhân tạo, dữ liệu, quyền, sở hữu trí tuệ

***
Thế giới Trí tuệ nhân tạo AI - (Artificial Intelligence) từ lâu đã có câu thần chú “Không có dữ liệu, không có AI”[1]. Với Viện Dữ liệu Mở - ODI (Open Data Institute), một tổ chức phi lợi nhuận có trụ sở tại Vương quốc Anh, cam kết thúc đẩy và cải thiện lòng tin vào dữ liệu, bao gồm cả dữ liệu mở, dữ liệu chia sẻ, và dữ liệu đóng, thì câu thần chú này tham chiếu tới cơ sở hạ tầng dữ liệu AI, bao gồm các tập dữ liệu, các công cụ, tiêu chuẩn, thực hành, và cộng đồng.
Trong sơ đồ trừu tượng vòng đời AI như được minh họa trên Hình 1, nhiều phần tập trung vào dữ liệu! Dữ liệu là nền tảng cho các mô hình AI. Dữ liệu cung cấp thông tin mà một mô hình máy học được đào tạo và học từ đó. Dữ liệu được thu thập, xử lý, giám tuyển, tổng hợp và sau đó được sử dụng trong mô hình. Dữ liệu được sử dụng để kiểm thử và kiểm chuẩn sự thành công của mô hình. Và dữ liệu được nhập vào để sử dụng sau khi mô hình đi vào hoạt động.
Việc xây dựng một hệ thống AI thường liên quan đến việc xác định nguồn cho lượng lớn dữ liệu và việc tạo lập các tập dữ liệu cho đào tạo, kiểm thử, thẩm định, và triển khai. Quá trình này là lặp đi lặp lại theo đó nó có thể đòi hỏi vài vòng đào tạo, kiểm thử và đánh giá cho tới khi kết quả mong muốn đạt được và dữ liệu đóng vai trò quan trọng trong từng bước.
Điều này giải thích vì sao AI lấy dữ liệu làm trung tâm (Data-centric AI) với trọng tâm nhằm vào cơ sở hạ tầng dữ liệu của AI - bao gồm các tập dữ liệu, các công cụ, tiêu chuẩn, thực hành, và cộng đồng - đang ngày càng trở nên quan trọng hơn bao giờ hết đối với việc phát triển và ứng dụng AI khắp trên thế giới.
Mặt khác, điều này cũng đặt ra một loạt các vấn đề cho các quốc gia/tổ chức muốn hướng đến việc ứng dụng và phát triển AI an toàn, minh bạch và có trách nhiệm hơn.
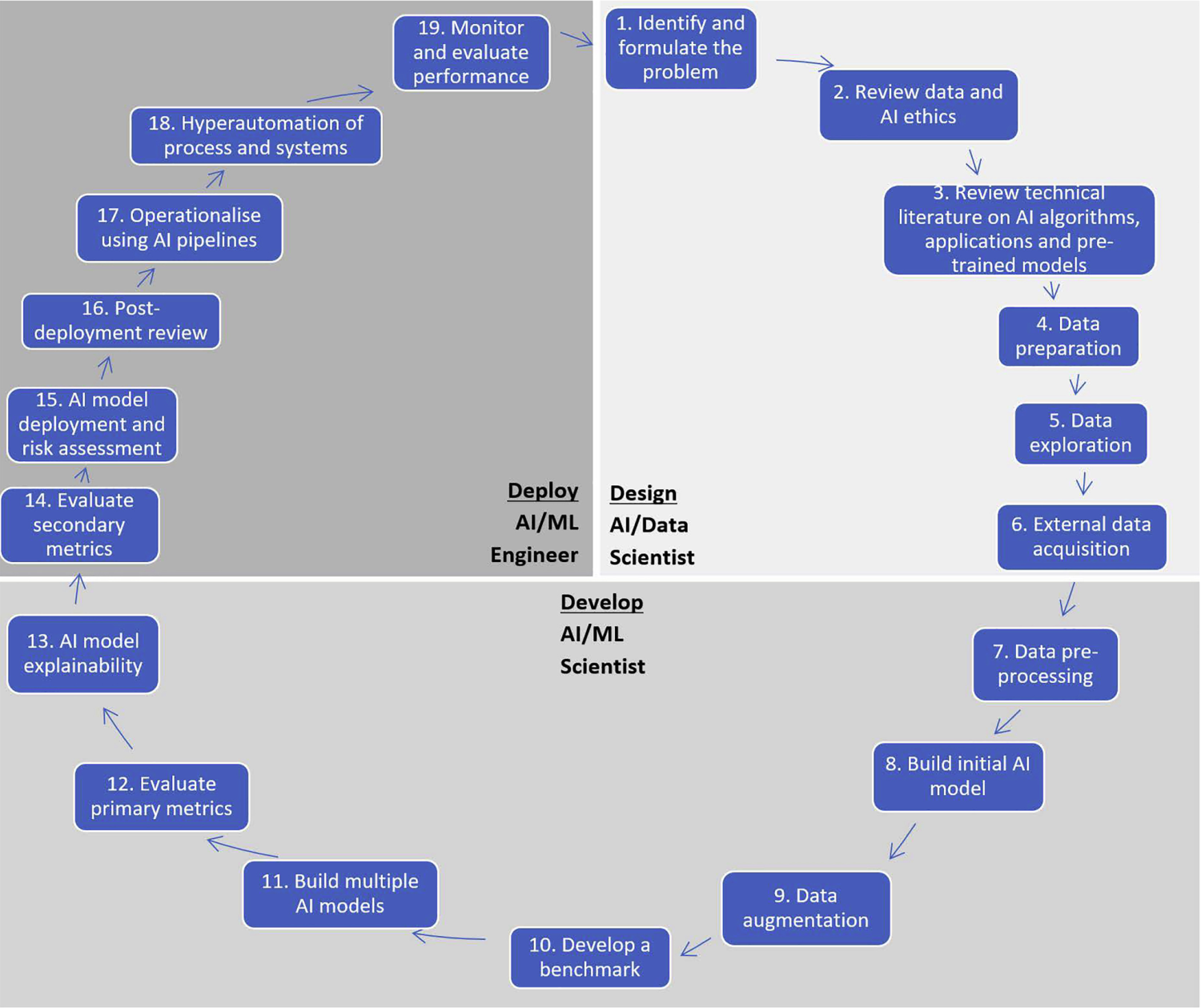
Hình 1. Vòng đời trí tuệ nhân tạo: Từ khái niệm hóa tới sản xuất – ScienceDirect”, với ML là viết tắt của Machine Learning - Máy học
1. Minh bạch xung quanh dữ liệu được sử dụng để đào tạo các mô hình AI[2]
Hầu hết các hãng AI hàng đầu đã từ chối mở ra các chi tiết về dữ liệu họ đã sử dụng để đào tạo và kiểm thử các mô hình AI. Chỉ số Minh bạch Mô hình của Quỹ Stanford (Stanford Foundation Model Transparency index) đánh giá các mô hình nền tảng chủ chốt cung cấp xương sống của nhiều công cụ và dịch vụ AI, đã chứng minh rằng minh bạch liên quan đến dữ liệu được sử dụng là rất thấp so với các khía cạnh minh bạch khác. Trong tài liệu được xuất bản khi khởi xướng mô hình GPT-4 của nó, OpenAI đã nêu rằng nó sẽ không chia sẻ thông tin chi tiết về ‘việc xây dựng tập dữ liệu’ và các khía cạnh khác của sự phát triển mô hình đó vì ‘bối cảnh cạnh tranh và ý nghĩa an toàn của các mô hình phạm vi rộng’ - một quyết định đã bị chỉ trích dữ dội bởi một số nhà nghiên cứu hàng đầu.
Dữ liệu nào được sử dụng để xây dựng các hệ thống AI là quan trọng; nhưng mức độ hiểu biết của những người phát triển, triển khai và sử dụng hệ thống AI về các thành kiến, hạn chế và nghĩa vụ pháp lý liên quan đến việc sử dụng dữ liệu này cũng quan trọng không kém để đảm bảo hệ thống được triển khai một cách có trách nhiệm. Xa hơn nữa, người dùng hệ thống AI và những người bị ảnh hưởng bởi việc sử dụng chúng có nhiều khả năng tin tưởng chúng hơn nếu họ hiểu cách chúng được phát triển. Về lý thuyết, nếu hệ thống được giải thích đúng, 'người dùng sẽ biết khi nào nên tin tưởng vào dự đoán của hệ thống và khi nào nên áp dụng phán đoán của riêng họ'.
Trong một cuộc điều tra của mình, Washington Post đã kết luận rằng 'nhiều công ty không ghi lại thành tài liệu nội dung dữ liệu đào tạo của họ - ngay cả trong nội bộ - vì sợ tìm thấy thông tin cá nhân có thể nhận dạng được và/hoặc tài liệu có bản quyền và dữ liệu khác bị lấy mà không có sự đồng ý'.
Có nhà nghiên cứu ví điều này như 'điều khiển một máy bay thương mại chở đầy nhiên liệu thí điểm chưa được thử nghiệm là hành vi cẩu thả. Các quy tắc yêu cầu các hãng hàng không cho chúng ta biết những gì có trong bình nhiên liệu không cản trở sự đổi mới. Ngay cả việc triển khai các mô hình trong phạm vi công cộng mà không có sự giám sát cũng là hành vi cẩu thả'.
2. Điều chỉnh chế độ sở hữu trí tuệ để các mô hình AI được đào tạo công bằng[3]
Các công ty AI đưa ra các lập luận khác nhau về lý do tại sao việc thu thập dữ liệu để đào tạo AI nên được phép. Tuy nhiên, nhiều người đã không đồng tình với việc này.
Một số chủ sở hữu bản quyền lớn đã đưa các công ty AI ra tòa vì cách họ đào tạo mô hình của mình, một số yêu cầu bồi thường thiệt hại tài chính đáng kể hoặc thậm chí là phá hủy chúng. Ví dụ, Getty Images kiện Stability AI vì cáo buộc đào tạo mô hình AI của nó trên hơn 12 triệu bức ảnh mà không được phép hay đền bù. Vào tháng 7 năm 2023, tác giả Sarah Silverman đã kiện OpenAI vì sử dụng tập dữ liệu Books3 bao gồm các tác phẩm viết của hàng nghìn tác giả. Cùng thời điểm đó, một bức thư được hơn 8.000 tác giả ký tên lập luận rằng ‘hàng triệu cuốn sách, bài báo, tiểu luận và thơ có bản quyền cung cấp 'thức ăn' cho các hệ thống AI, những bữa ăn vô tận mà không có hóa đơn thanh toán nào". Một cuộc khảo sát do Hiệp hội tác giả thực hiện cho thấy 90% các nhà văn tin rằng họ nên được đền bù nếu tác phẩm của họ được sử dụng để đào tạo các mô hình AI.
Việc đào tạo các mô hình dựa trên nội dung của web đã gây ra rạn nứt ngay cả trong các cộng đồng có ý định để các tác phẩm của họ được tiêu thụ rộng rãi. Trong năm 2023, nhiều diễn đàn lớn nhất của Reddit đã bị làm cho 'tối đen' để phản đối các kế hoạch của nền tảng này nhằm cho phép các nhà phát triển AI truy cập vào khối lượng lớn các thảo luận trên diễn đàn mà họ đã đóng vai trò quan trọng trong việc tạo ra chúng. Những người đóng góp cho Stack Overflow, một diễn đàn Internet dành cho các nhà phát triển, đã bị cấm khỏi trang web này sau khi họ xóa nội dung của mình để ngăn chặn việc sử dụng nội dung đó để đào tạo ChatGPT.”
Để chúng ta không bước vào "mùa đông dữ liệu" (Data Winter), cải cách chế độ sở hữu trí tuệ là chìa khóa để mang lại lợi ích của hệ sinh thái dữ liệu AI cho tất cả mọi người. Có nhà nghiên cứu cho rằng, "nếu bạn muốn Mô hình Ngôn ngữ Lớn - LLM (Large Language Model) có giá trị lâu dài, bạn cần phải có một hệ thống xã hội đi kèm, trong đó con người tiếp tục sản xuất kiến thức, nghệ thuật và thông tin khiến chúng trở nên có giá trị. Các hệ thống sở hữu trí tuệ không có động lực để sản xuất kiến thức có giá trị của con người sẽ khiến LLM ngày càng trở nên vô giá trị theo thời gian".
Chúng ta thực sự cần một chế độ sở hữu trí tuệ cân bằng giữa lợi ích mà AI mang lại và lợi ích của tất cả các bên tạo ra dữ liệu để nuôi dưỡng các mô hình AI phát triển. Nội dung ngay bên dưới đây nói lên điều này.
Đề xuất từ xã hội dân sự, giới công nghiệp và các tác nhân phi chính phủ khác
Ở một mức độ nào đó, thị trường đang bắt đầu phản ứng. Những người nắm giữ bản quyền lớn - bao gồm các hãng tin tức, hãng thu âm, hãng phim - đã có động thái thực hiện các thỏa thuận cấp phép với các công ty AI. Riêng OpenAI đã ký các thỏa thuận với Associated Press, Shutterstock và Axel Springer. Thỏa thuận của Google với Reddit để truy cập vào dữ liệu diễn đàn của mình được cho là trị giá 60 triệu đô la mỗi năm. Các nhà phát triển mô hình KL3M đưa ra một điểm bán hàng để thể hiện là nó được đào tạo trên 'một tập dữ liệu đào tạo được giám tuyển gồm các tài liệu pháp lý, tài chính và quy định', dành cho các khách hàng 'không muốn bị lôi kéo vào các vụ kiện về sở hữu trí tuệ như OpenAI, Stability AI và những công ty khác đã từng bị'. Fairly Trained là một tổ chức phi lợi nhuận mới được thành lập để chứng nhận rằng các công ty AI đã đào tạo các mô hình của họ dựa trên nội dung được cấp phép.
Nhưng rốt cuộc ai sẽ hưởng lợi từ một hệ sinh thái AI phụ thuộc vào việc cấp phép tốn tiền? Đã có ý kiến cho rằng 'nếu chúng ta kết thúc trong một hệ thống mà bạn chỉ có thể đào tạo các mô hình AI tốt dựa trên dữ liệu được cấp phép tốn tiền, thì sẽ có nguy cơ có sự tập trung quyền lực rất lớn. Có thể không phải người dùng, nghệ sĩ hoặc người sáng tạo nội dung sẽ được hưởng lợi từ điều này mà là các công ty lớn và hãng phim Hollywood sẽ giao dịch quyền của họ và không phân phối lại'. Theo Sáng kiến Nguồn Mở, một hệ sinh thái AI phụ thuộc quá nhiều vào việc cấp phép có thể trở nên kém đa dạng và cạnh tranh hơn, vì các công ty nhỏ và các học giả không có đủ khả năng tài chính để ra tòa hoặc ký kết các thỏa thuận song phương để cấp phép cho dữ liệu.
Ngoài ra còn có các nỗ lực mới nhằm tạo ra các cơ chế cho những người nắm giữ quyền nhỏ hơn, cá nhân riêng lẻ kiểm soát cách sử dụng các tác phẩm của họ. Đôi khi được mô tả là 'các mức đồng ý cho AI' hoặc 'dấu hiệu ưu tiên', chúng bao gồm các giao thức xuất bản web mới (ví dụ: Giao thức Đặt chỗ Khai thác Dữ liệu và Văn bản của W3C), các công cụ kỹ thuật (ví dụ: Nightshade[4]) và giấy phép dữ liệu (ví dụ: Giấy phép Dữ liệu Mở Chung, [Open Data Commons Licences]).
3. Đảm bảo quyền của tất cả mọi người trong chuỗi cung ứng dữ liệu[5]
Có sự tham gia đáng kể của con người đằng sau dữ liệu được sử dụng để đào tạo các mô hình AI nền tảng. Con người thực hiện các nhiệm vụ mà các mô hình máy tính khó có thể sao chép, chẳng hạn như thu thập dữ liệu, lọc và kiểm duyệt dữ liệu và dán nhãn dữ liệu.
Thị trường toàn cầu cho loại công việc dữ liệu này được định giá 2 tỷ đô la vào năm 2022 và dự kiến sẽ tăng lên 17 tỷ đô la vào năm 2030. Hầu hết công việc này ở dạng 'nhiệm vụ nhỏ', được thực hiện ở các quốc gia có thu nhập thấp và trung bình.
Có một số rủi ro đối với điều kiện lao động và quyền trong chuỗi cung ứng dữ liệu này.
Đầu tiên, những người lao động làm việc với dữ liệu có thể tiếp xúc với những hình ảnh gây khó chịu và ngôn ngữ bạo lực mà không nhận được bất kỳ cảnh báo nào, điều cho thấy AI có thể là mối đe dọa đối với người lao động làm việc với nó.
Người lao động cũng có quyền được hưởng mức sống và an sinh xã hội. Tuy nhiên, một cuộc điều tra của tạp chí Time năm 2023 phát hiện ra rằng những người lao động AI ở Kenya được trả lương chưa đến 2 đô la một giờ và được phân loại là nhà thầu độc lập, không có các biện pháp bảo vệ an sinh xã hội như bảo hiểm y tế, đóng góp lương hưu và nghỉ phép có lương. Cũng có những cáo buộc về việc phá vỡ công đoàn và sa thải hàng loạt sau cuộc đình công năm 2019. Tình trạng bấp bênh này - kết hợp với việc kiểm duyệt nội dung một cách cực đoan - đã dẫn đến một cuộc khủng hoảng sức khỏe tinh thần trong số một số nhân viên dữ liệu Kenya. Một cuộc điều tra khác về các công ty làm chú thích dữ liệu đã mô tả một hệ thống mà biên lợi nhuận cao được ưu tiên hơn quyền và sự an toàn của người lao động. Các cuộc điều tra khác đã phát hiện ra rằng công việc dán nhãn dữ liệu được thực hiện bởi những người chưa thành niên.
Những người lao động làm việc với dữ liệu có xu hướng có quyền truy cập hạn chế tới các biện pháp khắc phục và giải quyết khiếu nại hiệu quả. Trong một số trường hợp, các công ty vẫn ẩn danh, biến mất và xuất hiện trở lại thường xuyên, khiến việc theo dõi và ngăn chặn những kẻ xấu trở nên vô cùng khó khăn. Một báo cáo của Aapti cho UNDP đã mô tả cách người lao động có thể bị phạt và bị loại khỏi hệ thống sau khi xếp hạng thấp hơn.
Những rủi ro này đối với quyền lao động có liên quan đến bất kỳ tổ chức nào của các quốc gia phát triển - ví dụ như Vương quốc Anh - khi sử dụng các mô hình AI đã được đào tạo ở nơi khác. Nhưng do sự thiếu minh bạch xung quanh dữ liệu được sử dụng để đào tạo nhiều mô hình AI phổ biến, các tổ chức thậm chí có thể không nhận thức được mức độ phụ thuộc của họ vào lực lượng lao động này.
Theo quan điểm bảo vệ dữ liệu, các mô hình AI nền tảng có nguy cơ mở rộng khoảng trống thực thi bảo vệ dữ liệu, theo đó, tính nghiêm ngặt của các quy định xung quanh dữ liệu cá nhân, trên giấy tờ, không phù hợp với hoạt động của các tổ chức trong thế giới thực. Ví dụ, các mô hình AI nền tảng được đào tạo bằng cách sử dụng lượng lớn dữ liệu được thu thập từ khắp web, với nhiều nhà phát triển mô hình dường như nghĩ rằng bất kỳ dữ liệu công khai nào cũng là trò chơi công bằng. Kết quả là, mười hai cơ quan bảo vệ dữ liệu quốc gia, bao gồm Văn phòng Ủy viên thông tin của Vương quốc Anh, đã xuất bản một tuyên bố chung để làm rõ rằng việc thu thập hàng loạt thông tin cá nhân từ web để đào tạo AI có thể cấu thành hành vi vi phạm dữ liệu có thể báo cáo ở nhiều quyền tài phán.
Nhiều công ty hiện cũng đang thay đổi các điều khoản dịch vụ của họ để cho phép họ sử dụng dữ liệu do người dùng tạo ra để đào tạo các mô hình AI mới. Meta gần đây đã công bố những thay đổi đối với chính sách về quyền riêng tư của mình, tin rằng họ có lợi ích hợp pháp để phủ nhận quyền bảo vệ dữ liệu của người dùng để phát triển 'công nghệ trí tuệ nhân tạo'. Đã có nhà hoạt động bảo vệ dữ liệu và luật sư chỉ trích những thay đổi này vì sự mơ hồ của chúng và cho biết rằng 'điều này rõ ràng là trái ngược với việc tuân thủ [bảo vệ dữ liệu]'.
Tài liệu của ODI xuất bản năm 2024 với tiêu đề: ‘Xây dựng tương lai tốt hơn với dữ liệu và AI: sách trắng’[6] nêu một vài ví dụ nổi bật về việc phát triển AI vi phạm các quyền: Vào tháng 3/2023, cơ quan bảo vệ dữ liệu của Ý đã tạm thời đình chỉ ChatGPT vì lo ngại về việc xử lý dữ liệu cá nhân để đào tạo hệ thống. Tại nước Mỹ, một vụ kiện ở California tuyên bố rằng các mô hình nền tảng của OpenAI đã được đào tạo bất hợp pháp về "các cuộc trò chuyện riêng tư, dữ liệu y tế và thông tin về trẻ em". Hơn nữa, các nhà nghiên cứu đã chỉ ra rằng mô hình đào tạo của ChatGPT có thể khiến cho nó làm "rò rỉ" dữ liệu, chẳng hạn như địa chỉ thư điện tử và số điện thoại thực, bằng cách sử dụng các lời nhắc cụ thể.
Để giải quyết vấn đề dữ liệu có liên quan đến quyền riêng tư trong bối cảnh Nghị định Bảo vệ dữ liệu cá nhân của Việt Nam đã được ban hành ngày 17/04/2023 và đã có hiệu lực thi hành từ 01/07/2023, bên cạnh nhiều hoạt động khác, có thể cần xây dựng một Khung ra quyết định ẩn danh[7].
4. Đảm bảo quyền truy cập rộng tới dữ liệu để đào tạo các mô hình AI[8]
Theo truyền thống, máy học dựa vào các tập dữ liệu được tạo thủ công, thường là kịp thời để tạo ra hoặc khi khó tìm nguồn. Khi quy mô và nhu cầu về dữ liệu tăng lên, đã có sự chuyển dịch sang thu thập lượng lớn dữ liệu từ web và dựa nhiều hơn vào những người làm việc trong cộng đồng để tinh chỉnh và nhắc. Đối với thời đại hiện tại của các mô hình nền tảng - các tập dữ liệu được thu thập từ web như CommonCrawl và LAION cùng với quyền truy cập vào dữ liệu nền tảng công khai từ Wikipedia, Reddit và StackOverflow đã đóng vai trò trung tâm. Quyền truy cập mở và rộng rãi vào dữ liệu có thể được sử dụng cho AI là điều quan trọng nhằm đảm bảo một hệ sinh thái đa dạng và cạnh tranh của các nhà phát triển AI. Một nhà nghiên cứu nhấn mạnh rằng việc bảo vệ nguồn mở là rất quan trọng đối với hệ sinh thái AI để cho phép các công ty khởi nghiệp sáng tạo tham gia thị trường.
Tuy nhiên, đối với AI nền tảng, ngày càng có nhiều rào cản về quyền truy cập mở và rộng rãi tới dữ liệu công khai.
Việc truy cập vào các tập dữ liệu quy mô lớn đang ngày càng trở nên đắt đỏ, với chi phí dự kiến sẽ tăng vọt khi nhu cầu tiếp tục tăng. Một phần là do tính hữu ích của các tập dữ liệu liên quan nhiều hơn đến chất lượng, thay vì số lượng/quy mô và do đó phụ thuộc rất nhiều vào sự giám tuyển của con người. Một số nhà xuất bản web cũng bắt đầu hạn chế quyền truy cập tới dữ liệu, với gần 14% các trang web phổ biến nhất chặn bot của Common Crawl - thường là để bảo vệ sở hữu trí tuệ và có khả năng là để đạt được các thỏa thuận riêng tư sinh lợi trực tiếp với các công ty AI. Việc đóng dữ liệu này có lợi cho các tổ chức lớn vốn đã có kho dữ liệu, có đủ khả năng tài chính để ra tòa và có thể tham gia vào các thỏa thuận song phương để cấp phép dữ liệu. Các đối thủ cạnh tranh nhỏ và học giả không thể tiếp cận các chiến lược này. Do đó, làn sóng Mô hình Ngôn ngữ Lớn - LLM (Large Language Models) tiếp theo có nguy cơ được các công ty tư nhân xây dựng dựa trên các tập dữ liệu đóng. Ngoài ra, việc theo dõi hiệu suất của các mô hình nền tảng vẫn còn nhiều thách thức do thiếu dữ liệu và chuẩn mực có thể truy cập công khai.
Các tổ chức nguồn mở có vai trò quan trọng trong việc hỗ trợ hệ sinh thái chống lại việc đóng lại dữ liệu. Ví dụ, Clement Delangue, CEO của Hugging Face, đã làm chứng trước Quốc hội Mỹ về nhu cầu "tính mở về mặt đạo đức" trong phát triển AI, điều này sẽ cho phép các nhà nghiên cứu ngoài một vài công ty công nghệ lớn tiếp cận công nghệ. Việc sử dụng lại dữ liệu là rất quan trọng để bảo tồn các tập dữ liệu được truy cập rộng rãi, vì "việc làm cho một tập dữ liệu sẵn sàng cho hoạt động nghiên cứu và phát triển hơn nữa có thể giúp cập nhật dữ liệu vì các nhà nghiên cứu/nhà phát triển khác có thể đóng góp dữ liệu mới".
5. Trao quyền cho mọi người trong việc chia sẻ và sử dụng dữ liệu cho AI[9]
Việc đạt được các lợi ích kinh tế và xã hội của AI phụ thuộc rất nhiều vào việc tin tưởng vào công nghệ. Đã có nhiều lời kêu gọi rộng rãi về việc tham gia nhiều hơn vào AI như một phương tiện để xây dựng các giải pháp đáng tin cậy bằng thiết kế thay vì cố gắng giành được lòng tin đó sau đó. Các mô hình nền tảng là một bước thay đổi so với các loại AI trước đó về hiệu suất, rủi ro và tác động - do đó, các cuộc thảo luận về thời điểm khi nào và cách sử dụng AI như thế nào cần phải tận dụng chuyên môn và ý kiến của nhiều người và cộng đồng hơn.
AI và dữ liệu có mối liên hệ chặt chẽ với nhau – không có dữ liệu thì không có AI. Việc tiếp cận lượng lớn dữ liệu đã trở nên vô cùng quan trọng đối với với sự phát triển của AI - phần lớn dữ liệu này do công chúng tạo ra và bao gồm nội dung do người dùng tạo ra được thu thập từ Internet.
Hiện tại, các công ty AI đang tìm cách tiếp cận các tập dữ liệu lớn - đặc biệt có giá trị là dữ liệu từ các cộng đồng trực tuyến vì chúng được giám tuyển chặt chẽ và do đó có chất lượng tốt hơn hầu hết nội dung trên Internet. Một số công ty đang cấp phép và cung cấp dữ liệu này để tạo doanh thu, nhưng đã gặp phải sự phản đối từ những người đóng góp. Ví dụ, cộng đồng Reddit đã tham gia vào các cuộc đình công và sau đó đóng cửa các subreddit trên nền tảng mà đang bán dữ liệu của họ cho các công ty AI. Reddit sau đó đã tiếp quản một số subreddit và ký kết các thỏa thuận với Google và OpenAI. DeviantArt đã phải đảo ngược quyết định của nó sử dụng tác phẩm của các nghệ sĩ để đào tạo các mô hình AI theo mặc định; thay vào đó, người dùng hiện có thể chủ động đồng ý với việc sử dụng như vậy. StackOverflow đã đi xa đến mức chặn những người dùng đã xóa các đóng góp của họ để phản đối việc bán dữ liệu của họ cho OpenAI. Rõ ràng, việc xóa dữ liệu này có thể gây ra tác động dây chuyền đến các công ty AI cần dữ liệu đó.
Chúng ta cần vượt ra ngoài sự minh bạch và trách nhiệm giải trình để hướng đến một thế giới mà mọi người có thể tham gia một cách có ý nghĩa vào cách làm thế nào để dữ liệu được chính phủ, ngành công nghiệp và nhiều bên khác sử dụng. Việc trao quyền cho mọi người và các cộng đồng trong bối cảnh AI có nghĩa là cho phép họ định hình cách các thuật toán và dữ liệu cơ bản được thiết kế, triển khai và sử dụng như thế nào để mang lại lợi ích cho xã hội, môi trường và nền kinh tế.
Lời kết
Tất cả 5 vấn đề nêu trên là tóm tắt nội dung từ 5 khuyến nghị của ODI để có các can thiệp chính sách từ chính phủ Vương quốc Anh vào các tháng 6 và 7/2024, được nêu trong tài liệu ‘Xây dựng tương lai tốt hơn với dữ liệu và AI: sách trắng’, cụ thể:
Đảm bảo quyền truy cập rộng rãi vào dữ liệu chất lượng cao, được quản trị tốt từ khu vực công và tư để thúc đẩy thị trường AI đa dạng và cạnh tranh;
Thực thi bảo vệ dữ liệu và quyền lao động trong chuỗi cung ứng dữ liệu;
Trao quyền cho mọi người có tiếng nói nhiều hơn trong việc chia sẻ và sử dụng dữ liệu cho AI;
Cập nhật chế độ sở hữu trí tuệ để đảm bảo các mô hình AI được đào tạo theo cách ưu tiên sự tin tưởng và trao quyền cho các bên liên quan;
Tăng tính minh bạch xung quanh dữ liệu được sử dụng để đào tạo các mô hình AI có rủi ro cao.
Đồng điệu với những khuyến nghị của ODI cho chính phủ Vương quốc Anh là sáng kiến của nước Mỹ thúc đẩy sử dụng an toàn và có trách nhiệm trí tuệ nhân tạo (AI)[10] đã được Phó Tổng thống Kamala Haris công bố nhân chuyến thăm Vương quốc Anh và tham dự Hội nghị thượng đỉnh Toàn cầu về An toàn AI đầu tháng 11/2023, bên cạnh Khung quản lý rủi ro AI phiên bản 1.0 (AI RMF 1.0[11]) đã được Viện Tiêu chuẩn và Công nghệ Quốc gia Mỹ (NIST) công bố vào tháng 1/2023[12].
Hy vọng các khuyến nghị mà ODI đưa ra cho chính phủ Vương quốc Anh cũng như danh sách các rủi ro AI cần được quản lý như được liệt kê trong AI RMF của nước Mỹ cũng sẽ được các nhà hoạch định chính sách về AI của Việt Nam, cộng đồng AI và các bên liên quan của Việt Nam tham khảo, để định hướng ứng dụng và phát triển AI Việt Nam an toàn, minh bạch, có trách nhiệm và ‘nhân tính’ hơn trong tương lai. Quan trọng, là tất cả chúng ta đều hiểu rằng: AI không phải tất cả là màu hồng và hiện có vô số các vấn đề của nó, cả kỹ thuật và nhất là phi kỹ thuật của dữ liệu AI, cần phải được giải quyết.
Các chú giải
[1] Ben Snaith (2023): What do we mean by “without data, there is no AI”: https://theodi.cdn.ngo/media/documents/20231221_-_Data-centric_AI_Short_Paper_-_What_do_we_mean_by_without_data_there_3AEHdDW.pdf. Bản dịch sang tiếng Việt: https://www.dropbox.com/scl/fi/4un643ygfuksd28fm2v1c/20231221_-_Data-centric_AI_Short_Paper_-_What_do_we_mean_by_without_data_there_3AEHdDW_Vi-08082024.pdf?rlkey=bgkh73tdcn26d3cak5sw8pcbl&st=4v3edaqe&dl=0
[2] ODI (2024): Policy intervention 1: Increase transparency around the data used to train AI models: https://theodi.org/news-and-events/blog/policy-intervention-1-increase-transparency-around-the-data-used-to-train-ai-models/. Bản dịch sang tiếng Việt: https://giaoducmo.avnuc.vn/ai/can-thiep-chinh-sach-1-tang-cuong-minh-bach-xung-quanh-du-lieu-duoc-su-dung-de-dao-tao-cac-mo-hinh-ai-1256.html
[3] ODI (2024): Policy intervention 2: Update our intellectual property regime to ensure AI models are trained fairly: https://theodi.org/news-and-events/blog/policy-intervention-2-update-our-intellectual-property-regime-to-ensure-ai-models-are-trained-fairly/. Bản dịch sang tiếng Việt: https://giaoducmo.avnuc.vn/ai/can-thiep-chinh-sach-2-cap-nhat-che-do-so-huu-tri-tue-cua-chung-ta-de-dam-bao-cac-mo-hinh-ai-duoc-dao-tao-cong-bang-1257.html
[4] Nightshade: What Is Nightshade?: https://nightshade.cs.uchicago.edu/whatis.html. Nightshade biến đổi hình ảnh thành các mẫu "độc" (“poison” samples), do đó, các mô hình đào tạo trên chúng mà không có sự đồng ý sẽ thấy mô hình của họ học được các hành vi không thể đoán trước, lệch khỏi các chuẩn mực mong đợi, ví dụ: lời nhắc yêu cầu hình ảnh một con bò đang bay trong không gian thay vào đó có thể nhận được hình ảnh một chiếc túi xách đang trôi nổi trong không gian.
[5] ODI (2024): Policy intervention 3: Enforcing people’s rights in the data supply chain: https://theodi.org/news-and-events/blog/policy-intervention-3-enforcing-peoples-rights-in-the-data-supply-chain/. Bản dịch sang tiếng Việt: https://giaoducmo.avnuc.vn/ai/can-thiep-chinh-sach-3-thuc-thi-quyen-cua-moi-nguoi-trong-chuoi-cung-ung-du-lieu-1258.html
[6] ODI (2024): Building a better future with data and AI: a white paper: https://theodi.cdn.ngo/media/documents/Building_a_better_future_with_data_and_AI__a_white_paper.pdf, p.8. Bản dịch sang tiếng Việt: https://www.dropbox.com/scl/fi/g9lcleqvgn4r6vhcmwt5g/Building_a_better_future_with_data_and_AI__a_white_paper_Vi-28072024.pdf?rlkey=6q88tf4qo1g4bahbutdvkiinj&dl=0
[7] Lê Trung Nghĩa (tại Security Bootcamp 2023): Nghị định Bảo vệ dữ liệu cá nhân và một vài gợi ý triển khai: https://giaoducmo.avnuc.vn/bai-viet-toan-van/nghi-dinh-bao-ve-du-lieu-ca-nhan-va-mot-vai-goi-y-trien-khai-1016.html
[8] ODI (2024): Policy intervention 4: Ensuring broad access to data for training AI models: https://theodi.org/news-and-events/blog/policy-intervention-4-ensuring-broad-access-to-data-for-training-ai-models/. Bản dịch sang tiếng Việt: https://giaoducmo.avnuc.vn/ai/can-thiep-chinh-sach-4-dam-bao-quyen-truy-cap-rong-toi-du-lieu-de-dao-tao-cac-mo-hinh-ai-1259.html
[9] ODI (2024): Policy intervention 5: Empowering people to have more of a say in the sharing and use of data for AI: https://theodi.org/news-and-events/blog/policy-intervention-5-empowering-people-to-have-more-of-a-say-in-the-sharing-and-use-of-data-for-ai/. Bản dịch sang tiếng Việt: https://giaoducmo.avnuc.vn/ai/can-thiep-chinh-sach-5-trao-quyen-cho-moi-nguoi-de-co-tieng-noi-nhieu-hon-trong-viec-chia-se-va-su-dung-du-lieu-cho-ai-1260.html
[10] White House (2023): FACT SHEET: Vice President Harris Announces New U.S. Initiatives to Advance the Safe and Responsible Use of Artificial Intelligence: https://www.whitehouse.gov/briefing-room/statements-releases/2023/11/01/fact-sheet-vice-president-harris-announces-new-u-s-initiatives-to-advance-the-safe-and-responsible-use-of-artificial-intelligence/. Bản dịch sang tiếng Việt: https://giaoducmo.avnuc.vn/ai/to-tin-pho-tong-thong-harris-cong-bo-sang-kien-moi-cua-my-thuc-day-su-dung-an-toan-va-co-trach-nhiem-tri-tue-nhan-tao-ai-1249.html
[11] NIST (2023): Artificial Intelligence Risk Management Framework (AI RMF 1.0): https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf
[12] NIST (2023): AI Risk Management Framework: https://www.nist.gov/itl/ai-risk-management-framework. Bản dịch sang tiếng Việt: https://giaoducmo.avnuc.vn/ai/khung-quan-ly-rui-ro-ai-1251.html
(Bài viết cho Hội thảo tại sự kiện Security Bootcamp 2024 do Hiệp hội Internet Việt Nam và cộng đồng Security Bootcamp Việt Nam tổ chức trong các ngày 28-29/09/2024 tại Phú Quốc, Kiên Giang, với chủ đề: Humanity).
Tự do tải về bài viết định dạng PDF ở địa chỉ DOI: 10.5281/zenodo.13852144
Tự do tải về bài trình chiếu tại hội thảo ở địa chỉ:
X (Tweet): https://x.com/nghiafoss/status/1839859422300123435
Xem thêm:
Security Bootcamp 2024 - Humanity: nhân tính trong kỷ nguyên AI?
Sách tóm tắt thông tin về 10 năm Security Bootcamp (năm 2023)
Security Bootcamp 2024 thu hút hàng trăm chuyên gia an ninh mạng trong nước
Tác giả: Nghĩa Lê Trung
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Blog này được chuyển đổi từ http://blog.yahoo.com/letrungnghia trên Yahoo Blog sang sử dụng NukeViet sau khi Yahoo Blog đóng cửa tại Việt Nam ngày 17/01/2013.Kể từ ngày 07/02/2013, thông tin trên Blog được cập nhật tiếp tục trở lại với sự hỗ trợ kỹ thuật và đặt chỗ hosting của nhóm phát triển...
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
 ‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
 Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
 12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
 Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
 Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 ‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
 ‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
 Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Tài nguyên Giáo dục Mở trong kỷ nguyên AI
 cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
 Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
 Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025
Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025

