 Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam

Tree of Thoughts (ToT)
Theo: https://www.promptingguide.ai/techniques/tot
Đối với các nhiệm vụ phức tạp đòi hỏi sự khám phá hoặc tầm nhìn chiến lược, các kỹ thuật gợi ý truyền thống hoặc đơn giản không hiệu quả. Yao và cộng sự (2023) và Long (2023) gần đây đã đề xuất Cây Tư Duy - ToT (Tree of Thoughts), một khung khái quát hóa việc gợi ý theo chuỗi tư duy và khuyến khích việc khám phá các tư duy đóng vai trò là các bước trung gian để giải quyết vấn đề chung bằng mô hình ngôn ngữ.
ToT duy trì một cây tư duy, trong đó các tư duy đại diện cho các chuỗi ngôn ngữ mạch lạc đóng vai trò là các bước trung gian hướng tới việc giải quyết vấn đề. Cách tiếp cận này cho phép một LM tự đánh giá tiến trình thông qua các tư duy trung gian được tạo ra để giải quyết vấn đề thông qua một quá trình suy luận có chủ đích. Khả năng tạo ra và đánh giá các tư duy của LM sau đó được kết hợp với các thuật toán tìm kiếm (ví dụ: tìm kiếm theo chiều rộng và tìm kiếm theo chiều sâu) để cho phép khám phá các tư duy một cách có hệ thống bằng cách nhìn về phía trước và quay lại phía sau.
Khung ToT được minh họa dưới đây:
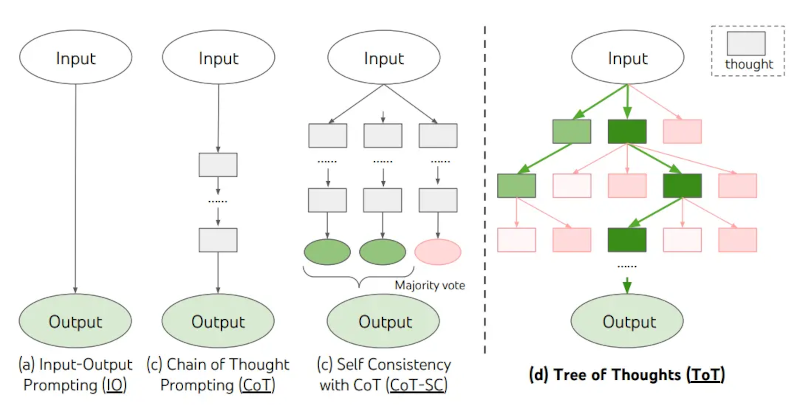
Image Source: Yao et el. (2023)
Khi sử dụng ToT, các nhiệm vụ khác nhau yêu cầu xác định số lượng ứng viên và số lượng suy nghĩ/bước. Ví dụ, như đã trình bày trong bài báo, Trò chơi 24 được sử dụng như một bài toán suy luận toán học, yêu cầu phân tích các suy nghĩ thành 3 bước, mỗi bước bao gồm một phương trình trung gian. Ở mỗi bước, các ứng viên tốt nhất với b=5 sẽ được giữ lại.
Để thực hiện BFS trong ToT cho nhiệm vụ Trò chơi 24, LM được yêu cầu đánh giá từng ứng viên suy nghĩ là "chắc chắn/có thể/không thể" liên quan đến việc đạt đến 24. Như các tác giả đã nêu, "mục tiêu là thúc đẩy các giải pháp từng phần đúng có thể được đưa ra phán đoán trong vài lần thử nhìn trước, và loại bỏ các giải pháp từng phần không thể dựa trên lý lẽ thông thường "quá lớn/quá nhỏ", và giữ phần còn lại là "có thể". Các giá trị được lấy mẫu 3 lần cho mỗi suy nghĩ. Minh họa quy trình như dưới đây:
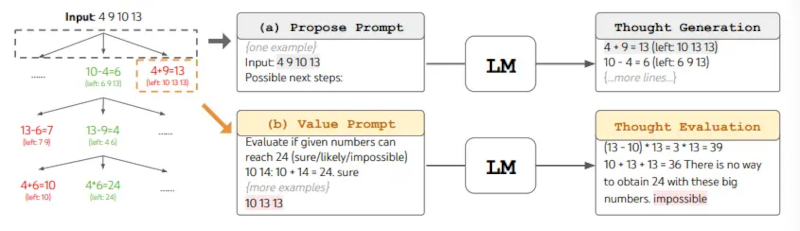
Nguồn ảnh: Yao et el. (2023)
Từ các kết quả được báo cáo trong hình bên dưới, ToT vượt trội hơn đáng kể so với các phương pháp nhắc khác:
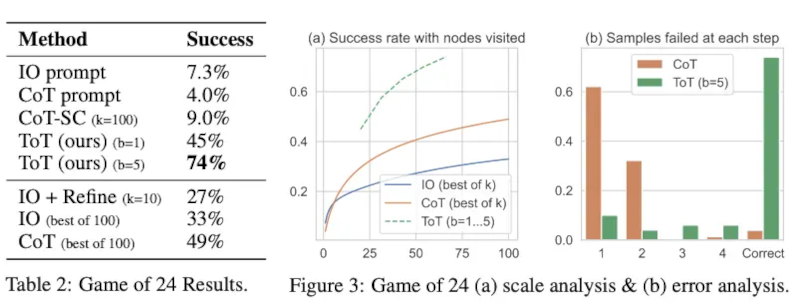
Image Source: Yao et el. (2023)
Ở cấp độ cao, các ý tưởng chính của Yao và cộng sự (2023) và Long (2023) khá tương đồng. Cả hai đều nâng cao khả năng giải quyết các vấn đề phức tạp của LLM thông qua tìm kiếm cây thông qua một cuộc trò chuyện nhiều vòng. Một trong những điểm khác biệt chính là Yao và cộng sự (2023) tận dụng tìm kiếm DFS/BFS/beam, trong khi chiến lược tìm kiếm cây (tức là khi nào cần quay lui và quay lui theo bao nhiêu cấp, v.v.) được đề xuất trong Long (2023) được điều khiển bởi một "Bộ điều khiển ToT" được đào tạo thông qua học tăng cường. Tìm kiếm DFS/BFS/Beam là các chiến lược tìm kiếm giải pháp chung chung, không thích ứng với các bài toán cụ thể. Ngược lại, một Bộ điều khiển ToT được đào tạo thông qua RL có thể học hỏi từ tập dữ liệu mới hoặc thông qua tự chơi (AlphaGo so với tìm kiếm tấn công thô bạo - brute force), và do đó hệ thống ToT dựa trên RL có thể tiếp tục phát triển và học hỏi kiến thức mới ngay cả với một LLM cố định.
Hulbert (2023) đã đề xuất Phương pháp Lời nhắc theo Cây Tư duy (Tree-of-Thought Prompting), áp dụng khái niệm chính từ các khuôn khổ ToT như một kỹ thuật gợi ý đơn giản, giúp LLM đánh giá các suy nghĩ trung gian chỉ trong một lời nhắc. Một ví dụ về gợi ý ToT là:
Hãy tưởng tượng ba chuyên gia khác nhau đang trả lời câu hỏi này.Tất cả các chuyên gia sẽ viết ra 1 bước suy nghĩ của mình,sau đó chia sẻ với cả nhóm.Sau đó, tất cả các chuyên gia sẽ chuyển sang bước tiếp theo, v.v.Nếu bất kỳ chuyên gia nào nhận ra mình sai ở bất kỳ điểm nào, họ sẽ rời đi.Câu hỏi là…
Sun (2023) đã đánh giá Cây tư duy bằng các thí nghiệm quy mô lớn và giới thiệu PanelGPT --- một ý tưởng về việc gợi ý trong các cuộc thảo luận nhóm giữa các LLM.
Về ‘Kỹ thuật viết lời nhắc’ ………. Phần trước ………. Phần tiếp theo
For complex tasks that require exploration or strategic lookahead, traditional or simple prompting techniques fall short. Yao et el. (2023) and Long (2023) recently proposed Tree of Thoughts (ToT), a framework that generalizes over chain-of-thought prompting and encourages exploration over thoughts that serve as intermediate steps for general problem solving with language models.
ToT maintains a tree of thoughts, where thoughts represent coherent language sequences that serve as intermediate steps toward solving a problem. This approach enables an LM to self-evaluate the progress through intermediate thoughts made towards solving a problem through a deliberate reasoning process. The LM's ability to generate and evaluate thoughts is then combined with search algorithms (e.g., breadth-first search and depth-first search) to enable systematic exploration of thoughts with lookahead and backtracking.
The ToT framework is illustrated below:
When using ToT, different tasks requires defining the number of candidates and the number of thoughts/steps. For instance, as demonstrated in the paper, Game of 24 is used as a mathematical reasoning task which requires decomposing the thoughts into 3 steps, each involving an intermediate equation. At each step, the best b=5 candidates are kept.
To perform BFS in ToT for the Game of 24 task, the LM is prompted to evaluate each thought candidate as "sure/maybe/impossible" with regard to reaching 24. As stated by the authors, "the aim is to promote correct partial solutions that can be verdicted within few lookahead trials, and eliminate impossible partial solutions based on "too big/small" commonsense, and keep the rest "maybe"". Values are sampled 3 times for each thought. The process is illustrated below:
From the results reported in the figure below, ToT substantially outperforms the other prompting methods:
At a high level, the main ideas of Yao et el. (2023) and Long (2023) are similar. Both enhance LLM's capability for complex problem solving through tree search via a multi-round conversation. One of the main difference is that Yao et el. (2023) leverages DFS/BFS/beam search, while the tree search strategy (i.e. when to backtrack and backtracking by how many levels, etc.) proposed in Long (2023) is driven by a "ToT Controller" trained through reinforcement learning. DFS/BFS/Beam search are generic solution search strategies with no adaptation to specific problems. In comparison, a ToT Controller trained through RL might be able learn from new data set or through self-play (AlphaGo vs brute force search), and hence the RL-based ToT system can continue to evolve and learn new knowledge even with a fixed LLM.
Hulbert (2023) has proposed Tree-of-Thought Prompting, which applies the main concept from ToT frameworks as a simple prompting technique, getting the LLM to evaluate intermediate thoughts in a single prompt. A sample ToT prompt is:
Imagine three different experts are answering this question.All experts will write down 1 step of their thinking,then share it with the group.Then all experts will go on to the next step, etc.If any expert realises they're wrong at any point then they leave.The question is...
Sun (2023) benchmarked the Tree-of-Thought Prompting with large-scale experiments, and introduce PanelGPT --- an idea of prompting with Panel discussions among LLMs.
Dịch: Lê Trung Nghĩa
letrungnghia.foss@gmail.com
Tác giả: Nghĩa Lê Trung
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Blog này được chuyển đổi từ http://blog.yahoo.com/letrungnghia trên Yahoo Blog sang sử dụng NukeViet sau khi Yahoo Blog đóng cửa tại Việt Nam ngày 17/01/2013.Kể từ ngày 07/02/2013, thông tin trên Blog được cập nhật tiếp tục trở lại với sự hỗ trợ kỹ thuật và đặt chỗ hosting của nhóm phát triển...
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
 ‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
 Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
 12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
 Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
 Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 ‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
 ‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
 Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Tài nguyên Giáo dục Mở trong kỷ nguyên AI
 cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
 Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
 Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025
Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025

