 Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam

Retrieval Augmented Generation (RAG)
Theo: https://www.promptingguide.ai/techniques/rag
Các mô hình ngôn ngữ mục đích chung có thể được tinh chỉnh để đạt được vài nhiệm vụ chung chẳng hạn như phân tích cảm xúc và nhận diện thực thể được đặt tên. Các nhiệm vụ đó thường không đòi hỏi kiến thức nền tảng bổ sung.
Đối với các tác vụ phức tạp và đòi hỏi nhiều kiến thức hơn, có thể xây dựng một hệ thống dựa trên mô hình ngôn ngữ, cho phép truy cập các nguồn kiến thức bên ngoài để hoàn thành tác vụ. Điều này cho phép tính nhất quán về dữ kiện cao hơn, cải thiện độ tin cậy của các phản hồi được tạo ra và giúp giảm thiểu vấn đề "ảo giác".
Các nhà nghiên cứu Meta AI đã giới thiệu một phương pháp gọi là Tạo sinh Tăng cường Truy xuất - RAG (Retrieval Augmented Generation) để giải quyết các tác vụ đòi hỏi nhiều kiến thức như vậy. RAG kết hợp một thành phần truy xuất thông tin với một mô hình tạo sinh văn bản. RAG có thể được tinh chỉnh và kiến thức nội bộ của nó có thể được sửa đổi một cách hiệu quả mà không cần phải đào tạo lại toàn bộ mô hình.
RAG lấy dữ liệu đầu vào và truy xuất một tập hợp các tài liệu liên quan/hỗ trợ dựa trên một nguồn (ví dụ: Wikipedia). Các tài liệu được nối theo ngữ cảnh với lời nhắc nhập ban đầu và được đưa vào trình tạo sinh văn bản, nơi tạo ra kết quả cuối cùng. Điều này làm cho RAG thích ứng với các tình huống mà dữ kiện có thể thay đổi theo thời gian. Điều này rất hữu ích vì kiến thức tham số của LLM là tĩnh. RAG cho phép các mô hình ngôn ngữ bỏ qua việc đào tạo lại, cho phép truy cập thông tin mới nhất để tạo sinh các đầu ra đáng tin cậy thông qua phương pháp tạo sinh dựa trên truy xuất.
Lewis và cộng sự, (2021) đã đề xuất một công thức tinh chỉnh đa năng cho RAG. Một mô hình seq2seq được đào tạo trước được sử dụng làm bộ nhớ tham số và một chỉ mục vectơ dày đặc của Wikipedia được sử dụng làm bộ nhớ phi tham số (được truy cập bằng bộ truy xuất thần kinh được đào tạo trước). Dưới đây là tổng quan về cách thức hoạt động của phương pháp này:
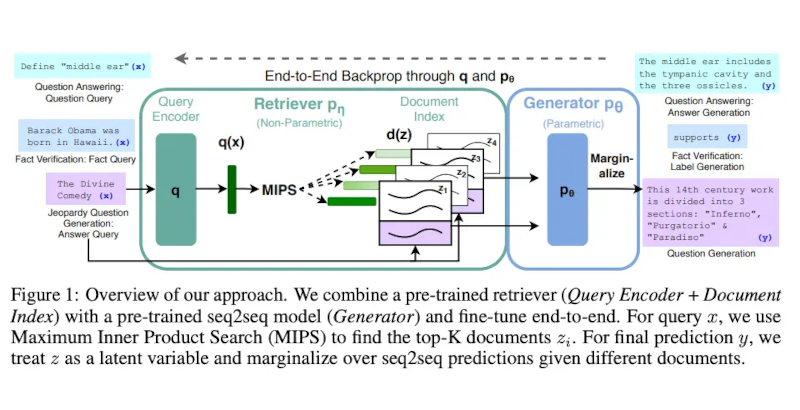
Image Source: Lewis et el. (2021)
RAG hoạt động mạnh mẽ trên một số tiêu chuẩn như Natural Questions, WebQuestions và CuratedTrec. RAG tạo ra các câu trả lời thực tế, cụ thể và đa dạng hơn khi được kiểm tra trên các câu hỏi MS-MARCO và Jeopardy. RAG cũng cải thiện kết quả xác minh dữ kiện FEVER.
Điều này cho thấy tiềm năng của RAG như một lựa chọn khả thi để cải thiện kết quả của các mô hình ngôn ngữ trong các nhiệm vụ đòi hỏi kiến thức chuyên sâu.
Gần đây, các phương pháp tiếp cận dựa trên bộ truy xuất này đã trở nên phổ biến hơn và được kết hợp với các chương trình LLM phổ biến như ChatGPT để cải thiện khả năng và tính nhất quán của dữ kiện.
Trường hợp sử dụng RAG: Tạo sinh tiêu đề bài báo học máy thân thiện
Dưới đây, chúng tôi đã chuẩn bị một hướng dẫn sổ tay giới thiệu việc sử dụng các Mô hình Ngôn ngữ Lớn - LLM (Large Language Model) nguồn mở để xây dựng hệ thống RAG nhằm tạo sinh tiêu đề bài báo học máy ngắn gọn và súc tích:
Tài liệu tham khảo
Tạo sinh Tăng cường Truy xuất cho Mô hình Ngôn ngữ Lớn: Khảo sát (tháng 12 năm 2023)
Tạo sinh Tăng cường Truy xuất: Hợp lý hóa việc tạo lập các mô hình xử lý ngôn ngữ tự nhiên thông minh (tháng 9 năm 2020)
Về ‘Kỹ thuật viết lời nhắc’ ………. Phần trước ………. Phần tiếp theo
General-purpose language models can be fine-tuned to achieve several common tasks such as sentiment analysis and named entity recognition. These tasks generally don't require additional background knowledge.
For more complex and knowledge-intensive tasks, it's possible to build a language model-based system that accesses external knowledge sources to complete tasks. This enables more factual consistency, improves reliability of the generated responses, and helps to mitigate the problem of "hallucination".
Meta AI researchers introduced a method called Retrieval Augmented Generation (RAG) to address such knowledge-intensive tasks. RAG combines an information retrieval component with a text generator model. RAG can be fine-tuned and its internal knowledge can be modified in an efficient manner and without needing retraining of the entire model.
RAG takes an input and retrieves a set of relevant/supporting documents given a source (e.g., Wikipedia). The documents are concatenated as context with the original input prompt and fed to the text generator which produces the final output. This makes RAG adaptive for situations where facts could evolve over time. This is very useful as LLMs's parametric knowledge is static. RAG allows language models to bypass retraining, enabling access to the latest information for generating reliable outputs via retrieval-based generation.
Lewis et al., (2021) proposed a general-purpose fine-tuning recipe for RAG. A pre-trained seq2seq model is used as the parametric memory and a dense vector index of Wikipedia is used as non-parametric memory (accessed using a neural pre-trained retriever). Below is a overview of how the approach works:
RAG performs strong on several benchmarks such as Natural Questions, WebQuestions, and CuratedTrec. RAG generates responses that are more factual, specific, and diverse when tested on MS-MARCO and Jeopardy questions. RAG also improves results on FEVER fact verification.
This shows the potential of RAG as a viable option for enhancing outputs of language models in knowledge-intensive tasks.
More recently, these retriever-based approaches have become more popular and are combined with popular LLMs like ChatGPT to improve capabilities and factual consistency.
RAG Use Case: Generating Friendly ML Paper Titles
Below, we have prepared a notebook tutorial showcasing the use of open-source LLMs to build a RAG system for generating short and concise machine learning paper titles:
Dịch: Lê Trung Nghĩa
letrungnghia.foss@gmail.com
Tác giả: Nghĩa Lê Trung
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Blog này được chuyển đổi từ http://blog.yahoo.com/letrungnghia trên Yahoo Blog sang sử dụng NukeViet sau khi Yahoo Blog đóng cửa tại Việt Nam ngày 17/01/2013.Kể từ ngày 07/02/2013, thông tin trên Blog được cập nhật tiếp tục trở lại với sự hỗ trợ kỹ thuật và đặt chỗ hosting của nhóm phát triển...
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
 ‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
 Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
 12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
 Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
 Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 ‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
 ‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
 Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Tài nguyên Giáo dục Mở trong kỷ nguyên AI
 cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
 Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
 Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025
Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025

