 Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Preprint Servers
Theo: https://info.orcid.org/documentation/workflows/preprint-workflow/
Trước khi xuất bản chính thức trên một tạp chí, các bài báo theo truyền thống được bình duyệt ngang hàng. Thường thì tạp chí sẽ chỉ xuất bản bài báo một khi các biên tập viên hài lòng là các tác giả đã giải quyết bất kỳ lo ngại nào có thể phát sinh từ quy trình bình duyệt đó.
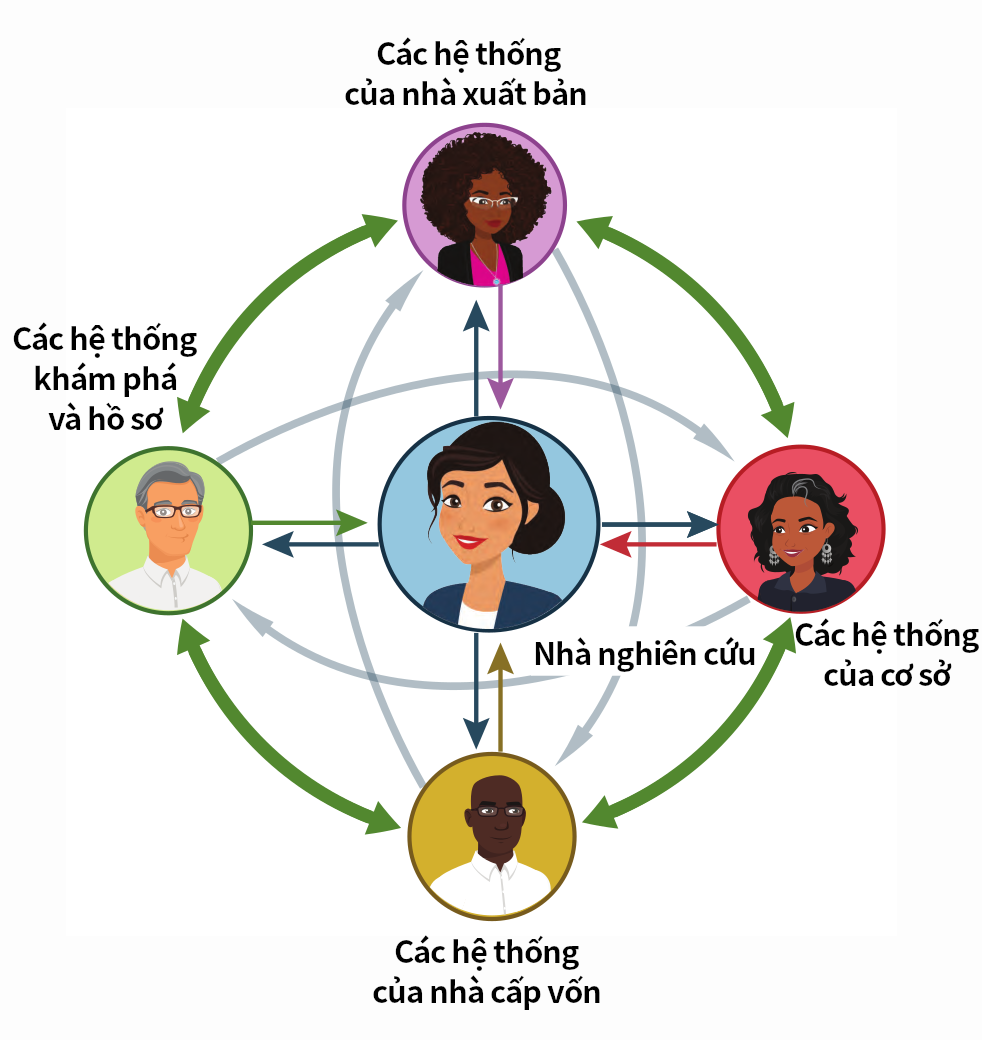
Chúng tôi biết rằng quy trình này có thể mất vài thời gian, và rằng không phải tất cả các ngành đều xuất bản tất cả các kết quả đầu ra lên các tạp chí. May thay, các nhà nghiên cứu có khả năng làm cho các kết quả đầu ra của họ sẵn sàng bằng việc tải lên một máy chủ preprint, tới lượt nó có thể cập nhật hồ sơ ORCID của họ nếu máy chủ preprint đó là một thành viên của ORCID. Quy trình cơ bản là như sau:
Tác giả gửi đệ trình bài báo tới máy chủ preprint
Dịch vụ của máy chủ preprint thu thập ORCID id của tác giả được xác thực và yêu cầu sự cho phép để tương tác với hồ sơ của họ, và lưu trữ sự cho phép đó.
Khi bản preprint đó được chấp nhận đối với máy chủ đó thì nhà cung cấp:
Đưa ORCID iD vào siêu dữ liệu của riêng nó, và bất kỳ siêu dữ liệu DOI nào.
Thêm bản preprint vào hồ sơ ORCID của tác giả, bao gồm cả ID của preprint đó (ví dụ, một DOI) và sử dụng dạng tác phẩm preprint với mối quan hệ “Self” (Bản thân). Điều này sẽ kết nối người đó với preprint đó.
Hiển thị logo iD xác thực cùng với tên tác giả của preprint đó và liên kết nó với hồ sơ ORCID của họ.
Dịch vụ đó cũng cho phép thu thập các iD xác thực cho bất kỳ đồng tác giả nào bằng việc gửi thư điện tử cho họ và yêu cầu họ xác thực và khẳng định đóng góp của họ.
Nếu bài báo đó được chấp nhận xuất bản trên một tạp chí được bình duyệt ngang hàng sau đó, thì nhà xuất bản có thể thêm bài báo trên tạp chí được bình duyệt ngang hàng vào hồ sơ ORCID, và đưa 2 mã nhận diện: một DOI cho bài báo trên tạp chí với quan hệ ‘Self’ và một DOI hoặc mã nhận diện của bản preprint gốc với quan hệ ‘Version of’ (Phiên bản của) nếu họ biết điều đó. Điều này sẽ nhóm các phiên bản lại cùng nhau trong hồ sơ ORCID, điều là hữu ích cho nhà nghiên cứu và những người xem hồ sơ đó.
Ví dụ

Liên kết bản preprint với các phiên bản được bình duyệt ngang hàng hoặc khác
ORCID hỗ trợ nhiều dạng quan hệ mã nhận diện bên ngoài:
Self - Tự bản thân: mã nhận diện tham chiếu chỉ tới tác phẩm đó và có thể được nhóm với các tác phẩm khác có cùng mã nhận diện. Ví dụ là một DOI
Part of - Phần của: tác phẩm là một phần của mã nhận diện này và không thể được nhóm với các tác phẩm khác. Ví dụ là một ISSN
Version of - Phiên bản của: các mã nhận diện áp dụng cho các phiên bản lựa chọn thay thế của tác phẩm và có thể được nhóm với self và version của các mã nhận diện. Được sử dụng để liên kết nhiều phiên bản của một tập hợp dữ liệu cùng nhau, hoặc để nhóm các preprint với phiên bản tài liệu được xuất bản.
Funded by - Được cấp vốn bởi: Các mã nhận diện này được sử dụng để liên kết việc cấp vốn với kết quả đầu ra nghiên cứu. Các mã nhận diện đó không được sử dụng trong việc tạo nhóm.
Các dạng mối quan hệ được sử dụng cho việc tạo nhóm các tác phẩm trong các hồ sơ ORCID của người sử dụng. Một tác phẩm y hệt có thể được thêm vào hồ sơ ORCID từ các nguồn khác nhau: nhiều kết nối đó làm cho thông tin về hồ sơ ORICD xác thực hơn. Ở những nơi các tác phẩm đó có một mã nhận diện chung (như một DOI, ISBN, .v.v.), chúng tự động được nhóm lại cùng nhau vì chúng đại diện cho một hạng mục y hệt. Lưu ý là vài mã nhận diện là phân biệt chữ hoa chữ thường và những gì xuất hiện sẽ là 2 phiên bản của cùng một mã nhận diện (ví dụ, “11abC” và “11ABC”) sẽ không nhóm được, trong khi vài mã nhận diện không phân biệt chữ hoa chữ thường và sẽ vẫn nhóm được ngay cả nếu các trường hợp đó là khác nhau (ví dụ, “10.125/1xyZ” và “10.125/1XYZ”). Nếu một tác phẩm không có mã nhận diện, nó không thể được nhóm.
Các lợi ích
Mọi thứ thường không đơn giản như vậy. Các iD và quyền ORCID có khả năng sẽ cần phải được chuyển từ hệ thống đệ trình sang hệ thống sản xuất và thậm chí có thể không có hệ thống để tác giả tương tác.
Chúng tôi vẫn nghĩ điều đó đáng làm. ORCID có thể giúp hợp lý hóa quy trình xuất bản, cải thiện quản lý tác giả và các cơ sở dữ liệu của người bình duyệt, và cải thiện độ chính xác tìm kiếm các kho dựa vào tên.
Các nhà xuất bản sử dụng ORCID để liên kết rõ ràng các tác giả và những người bình duyệt - và tất cả các phương án tên của họ - với tác phẩm nghiên cứu của họ, bằng việc nhúng các ORCID iD vào siêu dữ liệu ấn phẩm của họ và hiển thị chúng khi xuất bản hoàn thành. Bằng việc đưa các iD xác thực vào siêu dữ liệu của bạn, bạn có thể giải phóng các nhà nghiên cứu khỏi việc phải cập nhật thủ công hồ sơ ORCID của họ, giúp tăng tốc truyền thông các tác phẩm nghiên cứu, và giảm thiểu rủi ro các lỗi. Bạn cũng có thể sử dụng dữ liệu từ hồ sơ ORCID như tên các nhà nghiên cứu, lịch sử giáo dục, và các cơ sở liên kết hiện hành để nhập liệu cho các hồ sơ trong hệ thống của riêng bạn để tiết kiệm thời gian của người sử dụng của bạn và giảm thiểu các lỗi.
Các nhà nghiên cứu nằm ở tâm điểm của mọi điều mà các nhà xuất bản học thuật và nghiên cứu làm. Thông tin chính xác về tác giả và người bình duyệt là rất quan trọng cho việc đánh chỉ mục, tìm kiếm và phát hiện, theo dõi xuất bản, cấp vốn và thừa nhận ghi công sử dụng tài nguyên, và hỗ trợ cho bình duyệt ngang hàng.
Tham khảo thêm các bản dịch liên quan tới các quy trình làm việc của ORCID ở đây.
Before formal publication in a journal, articles are traditionally peer reviewed. Usually a journal will only publish an article once the editors are satisfied that the authors have addressed any concerns which may have arisen from the review process.
We are aware that this process can take some time, and that not all disciplines publish all outputs in journals. Luckily, researchers are able to make their outputs available by uploading to a preprint server, which in turn can update their ORCID record if that preprint server is an ORCID member. The basic workflow is as follows:
The author submits an article submission to the preprint server
The preprint server service collects the authenticated author’s ORCID iD and requests permission to interact with their record, and stores that permission.
When the preprint is accepted to the server the provider:
Includes the ORCID iDs in it’s own metadata, and any DOI metadata.
Add the preprint to the author’s ORCID record, including the preprint ID (e.g a DOI) and using the preprint work type with the relationship “Self”. This connects the person with the preprint.
Display the authenticated iD logo alongside the preprint author name and link it to their ORCID record.
The service also allows the collection of authenticated iDs for any co-authors by emailing them and asking them to authenticate and confirm their contribution.
If the article is accepted for publication in a peer reviewed journal at a later date, the publisher can add the peer reviewed journal article to the ORCID record, and include 2 identifiers: the DOI for the journal article with the relation ‘Self’ and the DOI or work-identifier of the original preprint with the relation ‘Version of’ if they know it. This will group the versions together in the ORCID record, which is helpful for the researcher and others viewing the record.
Linking preprints with peer reviewed or other versions
ORCID supports multiple external identifier relationship types:
Self: the identifier refers solely to that work and can be grouped with other works that have the same identifier. Example is a DOI
Part of: the work is part of this identifier and cannot be grouped with other works. Example is an ISSN
Version of: these identifiers apply to alternate versions of the work and can be grouped with self and version of identifiers. Used to relate multiple versions of a dataset together, or to group preprints with the published version of a paper.
Funded by: These identifiers are used to link funding to the research output. These identifiers are not used in grouping.
The relationships types are used for grouping works within the users ORCID records. The same work can be added to an ORCID record from different sources; these multiple connections make the information on the ORCID record more authoritative. Where these works have a common identifier (such as a DOI, ISBN, etc.), they are automatically grouped together as they represent the same item. Note that some identifiers are case sensitive and what appears to be two versions of the same identifier (e.g. “11abC” and “11ABC”) will not group, while some are case insensitive and will still group even if the cases are different (e.g. “10.125/1xyZ” and “10.125/1XYZ”). If a work does not have an identifier, it cannot be grouped.
We are aware that things are never this simple. The ORCID iDs and permissions potentially would need to be moved from the submission system to a production system, and there may not even be a system in place that authors interact with.
We still think it’s worth doing. ORCID can help streamline the publishing process, improve the management of author and reviewer databases, and enhance the accuracy of name-based repository searches.
Publishers use ORCID to clearly link authors and reviewers—and all their name variants—with their research work, by embedding ORCID iDs into their publication metadata and displaying them on finished publications. By including validated iDs in your metadata you can free researchers from having to manually update their ORCID records, help speed the communication of research works, and reduce the risk of errors. You can also use data from the ORCID record such as researchers’ names, education history, and current affiliations to populate profiles in your own system to save your users time and reduce errors.
Researchers are at the heart of everything that scholarly and research publishers do. Accurate author and reviewer information is vital to indexing, search and discovery, publication tracking, funding and resource use attribution, and supporting peer review.
Blogger: Lê Trung Nghĩa
letrungnghia.foss@gmail.com
Tác giả: Nghĩa Lê Trung
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Blog này được chuyển đổi từ http://blog.yahoo.com/letrungnghia trên Yahoo Blog sang sử dụng NukeViet sau khi Yahoo Blog đóng cửa tại Việt Nam ngày 17/01/2013.Kể từ ngày 07/02/2013, thông tin trên Blog được cập nhật tiếp tục trở lại với sự hỗ trợ kỹ thuật và đặt chỗ hosting của nhóm phát triển...
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
 ‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
 Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
 Hiểu các giấy phép CC và đào tạo AI: Một tóm tắt về pháp lý
Hiểu các giấy phép CC và đào tạo AI: Một tóm tắt về pháp lý
 12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
 ‘Từ nội dung của con người đến dữ liệu của máy móc. Giới thiệu tín hiệu CC’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
‘Từ nội dung của con người đến dữ liệu của máy móc. Giới thiệu tín hiệu CC’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
 Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
 Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
 Hướng dẫn nghiên cứu của khoa về ChatGPT và các công cụ AI
Hướng dẫn nghiên cứu của khoa về ChatGPT và các công cụ AI
 ‘Các nhà giáo dục AI sử dụng Tài nguyên Giáo dục Mở như thế nào? Một nghiên cứu trường hợp liên lĩnh vực về TNGDM cho giáo dục AI’ - bản dịch sang tiếng Việt
‘Các nhà giáo dục AI sử dụng Tài nguyên Giáo dục Mở như thế nào? Một nghiên cứu trường hợp liên lĩnh vực về TNGDM cho giáo dục AI’ - bản dịch sang tiếng Việt
 Khung AI mới của Vương quốc Anh (UK) đặt văn hóa lên trước mã
Khung AI mới của Vương quốc Anh (UK) đặt văn hóa lên trước mã
 cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
 ‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
 ‘Khuyến nghị về đạo đức của trí tuệ nhân tạo’ - bản dịch sang tiếng Việt
‘Khuyến nghị về đạo đức của trí tuệ nhân tạo’ - bản dịch sang tiếng Việt
 ‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt

