 Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Democratizing Participation in AI in Education
August 19, 2025 by opencontent
Theo: https://opencontent.org/blog/archives/7821
Bài được đưa lên Internet ngày: 19/08/2025
tl;dr – Hãy nghịch với generativetextbooks.org và cho tôi biết bạn nghĩ gì.
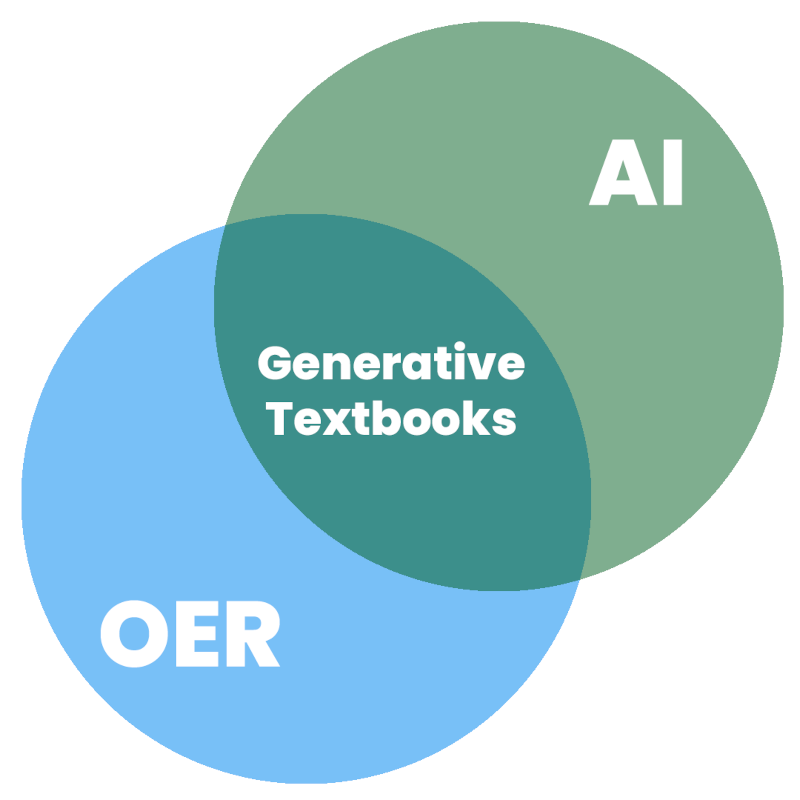
Đầu năm nay, tôi đã bắt đầu xây dựng nguyên mẫu một công cụ nguồn mở để học tập với AI nhằm khám phá những cách thức AI tạo sinh và Tài nguyên Giáo dục Mở (OER) có thể giao thoa. Tôi đặc biệt quan tâm đến việc kết hợp sức mạnh kỹ thuật của AI tạo sinh với sức mạnh có sự tham gia của OER, nhằm vừa tăng cường khả năng tiếp cận cơ hội giáo dục và vừa cải thiện kết quả học tập cho những học sinh được tiếp cận. Tôi đã viết một số bài viết sơ bộ về chủ đề này vào tháng 7 năm 2023, gọi những chế tác thu được từ việc kết hợp AI tạo sinh và OER là "sách giáo khoa tạo sinh" (bản dịch sang tiếng Việt) và vẫn đang tiếp tục suy ngẫm về chủ đề này.
Tôi muốn công cụ này khai thác mối quan hệ nhiều-nhiều giữa các chủ đề và kỹ thuật học tập. Nghĩa là, tôi muốn tận dụng lợi thế là bạn có thể học một chủ đề bằng nhiều kỹ thuật học tập khác nhau, và bạn cũng có thể sử dụng một kỹ thuật học tập để học nhiều chủ đề khác nhau. Ví dụ: bạn có thể học chương 1 bằng cả thẻ ghi nhớ và bài kiểm tra thực hành, và bạn có thể sử dụng thẻ ghi nhớ để học cả chương 1 và chương 2. Cả chủ đề cần học và các hoạt động mà người học tham gia để học chúng đều có thể được kết hợp và pha trộn (ở một mức độ nào đó).
Từ góc độ tham gia/dân chủ hóa, điều quan trọng đối với tôi là bất kỳ ai có thể biên soạn một cuốn sách giáo khoa mở cũng có thể biên soạn một cuốn sách giáo khoa tạo sinh. Công cụ này cần cung cấp trải nghiệm không cần mã, nhập từ vào hộp như Pressbooks cho các tác giả. Nhưng chính xác thì họ sẽ biên soạn cái gì?
nhóm các tuyên bố ngắn gọn, cụ thể về những gì người học cần học (tức là mục tiêu học tập),
tóm tắt các chủ đề người học cần học (những nội dung này không nhằm mục đích để học sinh đọc và học, mà nhằm mục đích cung cấp thêm bối cảnh cho mô hình để cải thiện độ chính xác của nó), và
các hoạt động học sinh có thể thực hiện để học.
Vào một thời điểm nào đó, bạn tôi (và cũng là một kỹ sư phần mềm rất tài năng) Josh Maddy đã tham gia. Những gì chúng tôi tạo ra có thể được gọi là hệ thống quản lý mẫu template lời nhắc giáo dục. Bên cạnh các mục tiêu học tập, tóm tắt chủ đề và hoạt động, chúng tôi đã thêm một mẫu lời nhắc "cấp độ sách" có thể được sử dụng để thiết lập giọng điệu, cá tính, giọng văn, định dạng phản hồi (ví dụ: Markdown), v.v. trên toàn bộ sách giáo khoa tạo sinh. Do đó, nếu bạn định tạo một sách giáo khoa tạo sinh với mười "chương", bạn sẽ tạo:
một mẫu lời nhắc cấp độ sách,
mười nhóm kết quả học tập,
mười bản tóm tắt được căn chỉnh theo chủ đề chương, và
một số hoạt động học tập.
Để học với hệ thống, người học chọn một sách giáo khoa tạo sinh, sau đó chọn một chủ đề để học, và sau đó chọn phương pháp học. Thông tin liên quan đến các lựa chọn của họ sau đó được tổng hợp vào định dạng mẫu template lời nhắc đó và lời nhắc hoàn chỉnh sẽ được chuyển đến một LLM để khởi tạo hoạt động học tập.
Vì chúng tôi cam kết về tính mở, chúng tôi đã mở mã nguồn chính công cụ này, sử dụng các mô hình trọng số mở và bổ sung hỗ trợ cho thông tin ghi công tác giả và giấy phép. Phiên bản đầu tiên của nguyên mẫu đã gửi lời nhắc đến một mô hình trọng số mở được lưu trữ trên Groq (hiện là máy chủ lưu trữ mô hình trọng số mở yêu thích của tôi) thông qua API của họ. Thiết kế này giúp dễ dàng hoán đổi nhiều mô hình trọng số mở khác nhau, bao gồm cả những mô hình bạn có thể đang lưu trữ cục bộ. (Tuy nhiên, tôi nhận ra rằng việc thiết lập các mô hình cục bộ có thể nằm ngoài khả năng của phần lớn sinh viên mà tôi hy vọng sẽ được hưởng lợi từ một công cụ như thế này, và việc tạo ra một trải nghiệm "hoàn toàn tự làm" thực sự thú vị nằm ngoài phạm vi của nguyên mẫu mà chúng tôi đang tạo ra. Nhưng tôi nghĩ rằng việc vận hành toàn bộ bộ công cụ này cục bộ là một vấn đề có thể được giải quyết bằng một số khoản tài trợ.)
Phản hồi ban đầu
Đầu mùa hè này, mặc dù tôi chưa sẵn sàng trình bày nguyên mẫu cho mọi người, nhưng tôi cảm thấy công việc thiết kế và phát triển đã làm rõ tư duy của tôi đủ để tôi có thể có những cuộc trò chuyện ý nghĩa về những ý tưởng làm nền tảng cho công việc. Do đó, tôi đã có một số cuộc trò chuyện với các nhà giáo dục đại học và cao đẳng tại Hoa Kỳ về AI. Tôi cho rằng mình không nên ngạc nhiên, nhưng có một chủ đề nổi lên rõ ràng từ những cuộc trò chuyện đó:
Giáo viên quan tâm nhiều hơn đến việc các công cụ AI được cung cấp miễn phí cho sinh viên sử dụng hơn là việc chúng có phải là công cụ mở hay không.
Mặc dù nguyên mẫu hoàn toàn là mã nguồn mở và sử dụng các mô hình trọng số mở, việc truy cập các mô hình đó thông qua API lại tốn kém. (Trong tương lai, khi chúng tôi có thể kết nối công cụ với các mô hình chạy cục bộ, chúng tôi có thể đưa phương pháp dựa trên API này trở lại.) Nhưng hiện tại, chúng tôi cần thay đổi hướng đi trong thiết kế nguyên mẫu. Có lúc, dường như không có cách nào để cung cấp các khả năng mà chúng tôi muốn theo cách miễn phí cho sinh viên.
Sau đó, chúng tôi đã tìm ra một giải pháp. Nó sẽ làm giảm trải nghiệm người dùng phần nào, nhưng sẽ cho phép người học sử dụng công cụ miễn phí. Giải pháp đó là gì? Ở bước cuối cùng của quy trình, thay vì chuyển lời nhắc đã hoàn thành đến một LLM trọng số mở thông qua API, chỉ cần sao chép lời nhắc vào bảng tạm của người dùng và chuyển tiếp chúng đến LLM mà họ chọn. Khi đến đó, họ chỉ cần nhập "CTRL-V" hoặc nhấp vào "Chỉnh sửa > Dán" và nhấn enter.
Thực tế, phương pháp này có một số lợi ích ngoài việc không phải tính phí cho mỗi mã thông báo để sử dụng công cụ. Thứ nhất, nó cho phép sinh viên sử dụng những mô hình tốt nhất trên thế giới thay vì các mô hình trọng số mở, vốn tuy tuyệt vời nhưng lại kém hơn các mô hình độc quyền về chất lượng. Thứ hai, nếu cơ sở đào tạo của sinh viên có chương trình LLM mà tất cả người học đều có quyền truy cập và có kinh nghiệm sử dụng, họ có thể sử dụng công cụ quen thuộc đó cho công việc của mình. Và cuối cùng, nếu họ không có tài khoản trả phí (trả phí cá nhân hoặc trả phí của cơ sở đào tạo), sinh viên có thể sử dụng đến giới hạn miễn phí của một mô hình và sau đó dễ dàng chuyển sang một mô hình khác để tiếp tục học tập.
Nhưng cách tiếp cận này cũng có những nhược điểm. Ngoài việc trải nghiệm người dùng hơi rời rạc, cách tiếp cận này còn gây khó khăn cho việc thu thập dữ liệu phân tích để cải tiến liên tục hoặc hỗ trợ nghiên cứu (mặc dù tôi đang nghiên cứu một số ý tưởng để khắc phục hạn chế này). Cũng có thể có những lo ngại về quyền riêng tư nếu (các) cấp độ sử dụng miễn phí của (các) mô hình mà người học chọn sử dụng không có sự đảm bảo quyền riêng tư chặt chẽ.
Công khai
Nguyên mẫu vẫn chỉ là một thử nghiệm chưa hoàn thiện, trái ngược với một sản phẩm đã được hoàn thiện. Nhưng giờ đây, nó đã sẵn sàng để bạn trải nghiệm. Hai lưu ý cần cân nhắc khi thực hiện:
Đầu tiên, cần phải nói - và cần phải nói đi nói lại nhiều lần - rằng một công cụ như hệ thống quản lý mẫu template lời nhắc giáo dục sẽ chỉ hỗ trợ việc học tập hiệu quả nếu các thành phần mẫu riêng lẻ được viết tốt. Mục tiêu cần phải rõ ràng, tóm tắt cần phải toàn diện và chính xác, và các hoạt động cần phải dựa trên nghiên cứu nghiêm ngặt về những gì thực sự hỗ trợ việc học tập của sinh viên. (Một lời nhắc hoạt động phù hợp với "phong cách học tập" của sinh viên sẽ không giúp ích gì.) "Vào rác, ra rác" chưa bao giờ đúng hơn trong bối cảnh của Mô hình Ngôn ngữ Lớn - LLM (Large Language Model). Công cụ này, theo nhiều cách, chỉ là một nơi để mọi người dễ dàng lưu trữ và quản lý các lời nhắc của họ. Vì vậy, hãy coi đây chủ yếu là một bản demo công nghệ - tôi chưa đầu tư nhiều thời gian và công sức vào nội dung demo. (Tôi vừa mượn một số nội dung mở từ Lumen và OpenStax và nhanh chóng xây dựng một vài hoạt động demo.) Nhưng đã có đủ nội dung để bạn có thể hình dung được những gì có thể làm được nếu chúng ta nỗ lực hơn nữa.
Thứ hai, tôi không nghĩ những sách giáo khoa tạo sinh này đã sẵn sàng để được sử dụng làm tài liệu học tập chính thức ngay lúc này – công cụ này cần nhiều chức năng hơn nữa trước khi bạn có thể cân nhắc điều đó. Tuy nhiên, tôi nghĩ rằng nó sẽ tạo ra những tài liệu bổ sung cực kỳ thú vị, và đó là cách tôi sẽ sử dụng chúng trong việc giảng dạy học kỳ này.
Vì vậy, hãy thử nghiệm với generativetextbooks.org và cho tôi biết suy nghĩ của bạn. Bạn có thể dùng thử trải nghiệm người học mà không cần đăng nhập, nhưng bạn sẽ cần đăng nhập bằng Google để sử dụng các công cụ soạn thảo. (Và nếu bạn muốn thử nghiệm mã nguồn, hãy truy cập Github.) Và xin chân thành cảm ơn Lumen Learning đã hỗ trợ công việc này!
tl;dr – Go play around with generativetextbooks.org and let me know what you think.
Earlier this year I began prototyping an open source tool for learning with AI in order to explore ways generative AI and OER could intersect. I’m specifically interested in trying to combine the technical power of generative AI with the participatory power of OER, in order to both increase access to educational opportunity and improve outcomes for those students who access it. I did some preliminary writing on this topic back in July of 2023, calling the artifacts that result from combining generative AI and OER “generative textbooks” and have continued to ruminate on the topic.
I wanted the tool to exploit the many-to-many relationship between topics and study techniques. That is, I wanted to leverage the fact that you can study one topic using many different study techniques, and you can also use one study technique to study many different topics. For example, you can study chapter 1 using both flash cards and practice quizzes, and you can use flash cards to study both chapter 1 and chapter 2. Both the topics to be learned, and the activities learners engage in to learn them, can be mixed and matched (to some extent).
From a participatory / democratizing perspective, it was important to me that anyone who could author an open textbook could also author a generative textbook. The tool needed to provide a no-code, type-words-in-a-box experience like Pressbooks for authors. But what exactly would they author?
groups of short, specific statements of what learners should learn (i.e., learning objectives),
summaries of the topics learners should learn (these are not intended for students to read and learn from, they’re intended to provide extra context to the model to improve its accuracy), and
activities students can do in order to learn.
At some point my friend (and very talented software engineer) Josh Maddy got involved. What we ended up creating might be called an educational prompt template management system. In addition to the learning objectives, topic summaries, and activities we added a “book-level” prompt stub that can be used to establish tone, personality, voice, response format (e.g., Markdown), etc. across the entire generative textbook. Consequently, if you were going to create a generative textbook with ten “chapters,” you would create:
one book-level prompt stub,
ten groups of learning outcomes,
ten aligned summaries of chapter topics, and
some number of learning activities.
To study with the system, a learner selects a generative textbook, then selects a topic to study, and then selects a way to study. The information associated with their selections is then aggregated into the prompt template format and the completed prompt is passed to an LLM to kick off the learning activity.
Because we’re committed to openness, we open sourced the tool itself, used open weights models, and added support for attribution and license information. The first version of the prototype sent the prompt to an open weights model hosted on Groq (currently my favorite host of open weights models) via their API. This design makes it easy to swap in a range of different open weights models, including ones you might be hosting locally. (I recognize, though, that setting up local models is likely beyond the capability of the majority of students I hope will benefit from a tool like this, and that creating a truly delightful “done-for-you” experience is beyond the scope of this prototype we’re making. But I think running this whole toolkit locally is a problem that could be solved with some grant funding.)
Early Feedback
Earlier this summer, while I wasn’t ready to show the prototype to people I felt like the design and development work had clarified my thinking enough that I could have meaningful conversations about the ideas underpinning the work. Consequently, I had several conversations with US-based college and university educators about AI. I suppose I shouldn’t have been surprised, but one theme emerged loud and clear from those conversations:
Instructors are significantly more interested in AI tools being free for students to use than they are interested in whether or not the tools are open.
While the prototype was all open source and used open weights models, accessing those models via the API costs money. (In the future, when we’re able to connect the tool to locally running models, we can bring this API-based approach back.) But for now we needed to change course on the prototype design. For a while it seemed like there was no way to do provide the capabilities we wanted to provide in a way that could be free for students.
Then we struck upon a solution. It would degrade the user experience somewhat, but would allow learners to use the tool for free. That solution? At the last step in the process, rather than passing the completed prompt to an open weights LLM via an API, simply copy the prompt to the user’s clipboard and forward them to the LLM of their choice. When they get there, they just type “CTRL-V” or click “Edit > Paste” and hit enter.
There are actually some benefits to this approach beyond not having to charge people per token to use the tool. First, it lets students use the very best models in the world instead of the open weights models which, though terrific, lag behind the proprietary models in terms of quality. Second, if a student’s institution has an institutional LLM that all learners have access to and have experience using, they can use that familiar tool for their work. And finally, if they don’t have a paid account (either personally paid or institutionally paid), students can work up to the free limits of one model and then easily switch over to a different model to continue their learning.
But there are downsides to this approach as well. Beyond the user experience being a little disjointed, this approach makes it difficult to capture analytics data for continuous improvement or in support of research (though I’m working on some ideas to overcome this limitation). There may also be privacy concerns if the free usage tier(s) of the model(s) learners choose to use don’t have strong privacy assurances.
Making It Public
The prototype is still just that – an unpolished experiment as opposed to a polished product. But it’s ready for you to play with now. Two notes to consider as you do:
First, it should be said – and it should be said over and over again – that a tool like an educational prompt template management system will only support learning effectively if the individual template components are well written. The objectives need to be clear, the summaries need to be comprehensive and accurate, and the activities need to be grounded in rigorous research about what actually supports student learning. (An activity prompt that adapts to a student’s “learning style” isn’t going to help anything.) “Garbage in, garbage out” was never truer than it is in the context of LLMs. This tool is, in many ways, just a place for people to easily host and manage their prompts. So think about this as primarily a technology demo – I haven’t invested a lot of time and effort in the demo content. (I’ve just borrowed some open content from Lumen and OpenStax and quickly built a couple of demo activities.) But there’s enough there that you should be able to get a sense for what might be possible if we pushed on this a little harder.
Second, I don’t think these generative textbooks are ready to be adopted as primary course materials just yet – the tool would need a lot more functionality before you could consider that. I do think, however, that it makes for extremely interesting supplemental materials, and that’s the way I’ll be using them in my teaching this semester.
So please go play around with generativetextbooks.org and let me know what you think. You can try the learner experience without logging in, but you’ll need to login with Google to play with the authoring tools. (And if you want to play around in the source code, it’s on Github.) And many thanks to Lumen Learning for supporting this work!
Dịch: Lê Trung Nghĩa
letrungnghia.foss@gmail.com
Tác giả: Nghĩa Lê Trung
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Blog này được chuyển đổi từ http://blog.yahoo.com/letrungnghia trên Yahoo Blog sang sử dụng NukeViet sau khi Yahoo Blog đóng cửa tại Việt Nam ngày 17/01/2013.Kể từ ngày 07/02/2013, thông tin trên Blog được cập nhật tiếp tục trở lại với sự hỗ trợ kỹ thuật và đặt chỗ hosting của nhóm phát triển...
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
 ‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
 Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
 12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
 Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
 Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 ‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
 ‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
 cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
 Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
 Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
 Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025
Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025

