 Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam

AI, Instructional Design, and OER
January 23, 2023 by opencontent
Theo: https://opencontent.org/blog/archives/7129
Bài được đưa lên Internet ngày: 23/01/2023
Năm 2022 chứng kiến một số tiến bộ đáng kể trong trí tuệ nhân tạo. Ngưỡng "đáng kể" của tôi ở đây là những tiến bộ đã vượt ra khỏi phòng thí nghiệm và bản thảo trước khi in (preprints) của arXiv.org và chuyển thành các công cụ mà nhiều người đang sử dụng và thảo luận. Nhiều người nghĩ các công cụ chuyển văn bản thành hình ảnh như DALL-E, Stable Diffusion và Midjourney rất thú vị. Nhưng các Mô hình ngôn ngữ lớn (LLM), và đặc biệt là bản demo gần đây của ChatGPT, dường như đã khiến mọi người, từ giáo viên tiếng Anh trung học cơ sở đến CEO của Google, phải khiếp sợ. Quan hệ đối tác tiềm năng giữa OpenAI (nhà sản xuất ChatGPT) và Microsoft thậm chí có thể đưa ra thách thức thực chất đầu tiên đối với độc quyền tìm kiếm của Google mà chúng ta từng thấy - và điều đó nói lên điều gì đó. Trong khi hầu hết các cuộc đối thoại xung quanh AI và giáo dục dường như tập trung vào đánh giá, tôi nghĩ rằng những hàm ý đối với các nhà thiết kế hướng dẫn cũng cực kỳ quan trọng. Và, vì bạn phải chơi các bản hit, chúng ta hãy cùng xem tác động của chúng đối với OER là gì.
Về các nhà thiết kế hướng dẫn
Tôi nghĩ rằng nhiều người tin rằng các nhà thiết kế hướng dẫn là những người thực sự giỏi sử dụng LMS trong khuôn viên trường – những người có thể tạo ra các lớp học mới cho giảng viên, giúp giảng viên tải nội dung của họ lên LMS và thậm chí có thể giúp chỉnh sửa và sản xuất đa phương tiện. Thật không may, về cơ bản không có thứ nào trong số những thứ đó là thiết kế hướng dẫn. Thiết kế hướng dẫn là quá trình tận dụng những gì chúng ta hiểu về cách mọi người học để tạo ra những trải nghiệm nhằm tối đa hóa khả năng những người tham gia vào những trải nghiệm đó sẽ học được. Các nhà thiết kế hướng dẫn cần hiểu sâu sắc về cả nghiên cứu khoa học học tập và công nghệ giáo dục để tích hợp chúng một cách hiệu quả nhằm hỗ trợ việc học. Tải PDF giáo trình lên Blackboard không phải là thiết kế hướng dẫn. Bạn biết điều gì khác cũng không phải là thiết kế hướng dẫn không? Việc tạo ra các mô tả và giải thích chính xác về các sự kiện, lý thuyết và mô hình. Văn bản thô và hình ảnh tạo nên phần lớn những gì chúng ta gọi là sách giáo khoa. Tôi đã viết trước đây về sự khác biệt giữa tài nguyên thông tin và tài nguyên giáo dục. Wikipedia và các bách khoa toàn thư khác là tài nguyên thông tin. Tài liệu tham khảo và tài liệu kỹ thuật là tài nguyên thông tin. Phần lớn sách giáo khoa chủ yếu là tài nguyên thông tin. Điều phân biệt một nguồn giáo dục với một nguồn thông tin là nguồn thông tin thể hiện một số ứng dụng có chủ đích của kiến thức về cách mọi người học. Trước đây tôi đã lập luận rằng lượng công sức tối thiểu bạn có thể đầu tư để chuyển đổi một nguồn thông tin thành một nguồn giáo dục là thêm thực hành với phản hồi. Nhiệm vụ nghe có vẻ đơn giản đó nhanh chóng trở nên phức tạp khi bạn cân nhắc nghiên cứu về hình thức thực hành đó nên diễn ra, thời gian thực hành nên kéo dài bao lâu, khi nào nên lên lịch, loại phản hồi nào nên được cung cấp, liệu phản hồi nên đến ngay lập tức hay sau một thời gian trì hoãn, v.v.
Bây giờ, xin đừng hiểu lầm tôi - chắc chắn có một nghệ thuật và khoa học để tạo ra các nguồn thông tin chính xác, đẹp mắt. Đó chỉ là một nghệ thuật và khoa học khác với nghệ thuật và khoa học liên quan đến việc tạo ra các nguồn giáo dục. Tất cả các nguồn giáo dục đều bắt đầu là các nguồn thông tin, vì vậy chúng cực kỳ quan trọng đối với công việc chúng tôi làm với tư cách là nhà thiết kế hướng dẫn. Bạn có thể nói chúng là một loại cơ sở hạ tầng trí tuệ, theo cách Brett Frischmann sử dụng thuật ngữ này:
Cơ sở hạ tầng trí tuệ, chẳng hạn như nghiên cứu cơ bản, ý tưởng, công nghệ mục đích chung và ngôn ngữ, tạo ra lợi ích cho xã hội chủ yếu bằng cách tạo điều kiện cho nhiều hoạt động sản xuất hạ nguồn, bao gồm sản xuất thông tin, đổi mới và phát triển các sản phẩm và dịch vụ, cũng như giáo dục, xây dựng và tương tác cộng đồng, tham gia dân chủ, xã hội hóa và nhiều hoạt động có giá trị xã hội khác. (được nhấn mạnh thêm)
Các nguồn thông tin (đặc biệt là các nguồn được cấp phép mở) tạo điều kiện cho nhiều hoạt động sản xuất hạ nguồn, bao gồm cả việc tạo ra các nguồn giáo dục. Hoặc, theo ngôn ngữ mà tôi thường dùng trước đây, các nguồn thông tin là "cơ sở hạ tầng nội dung" mà các nhà thiết kế hướng dẫn xây dựng khi họ tạo ra các nguồn giáo dục.
LLM (Mô hình ngôn ngữ lớn) sẽ giúp việc tạo ra cơ sở hạ tầng nội dung dễ dàng hơn, nhanh hơn và rẻ hơn đáng kể
LLM sẽ tăng đáng kể tốc độ tạo ra các nguồn thông tin tạo nên cơ sở hạ tầng nội dung. Tất nhiên, các bản thảo của các nguồn thông tin này sẽ cần được xem xét và cần phải cải thiện - giống như trường hợp của tất cả các bản thảo đầu tiên - để đảm bảo tính chính xác và kịp thời. Nhưng có vẻ như LLM có thể giúp chúng ta hoàn thành 80% hoặc hơn nữa các bản thảo đầu tiên hợp lý nhanh hơn gấp nhiều lần, loại bỏ phần lớn chi phí liên quan đến phần này của quy trình. Sau đây là một ví dụ về những gì tôi đang nói đến. Hãy tưởng tượng bạn là một doanh nghiệp vừa và nhỏ được giao nhiệm vụ viết nội dung cho một cuốn sách giáo khoa kinh tế nhập môn. (Các ví dụ sau đây là từ ChatGPT.)
Định nghĩa và ví dụ
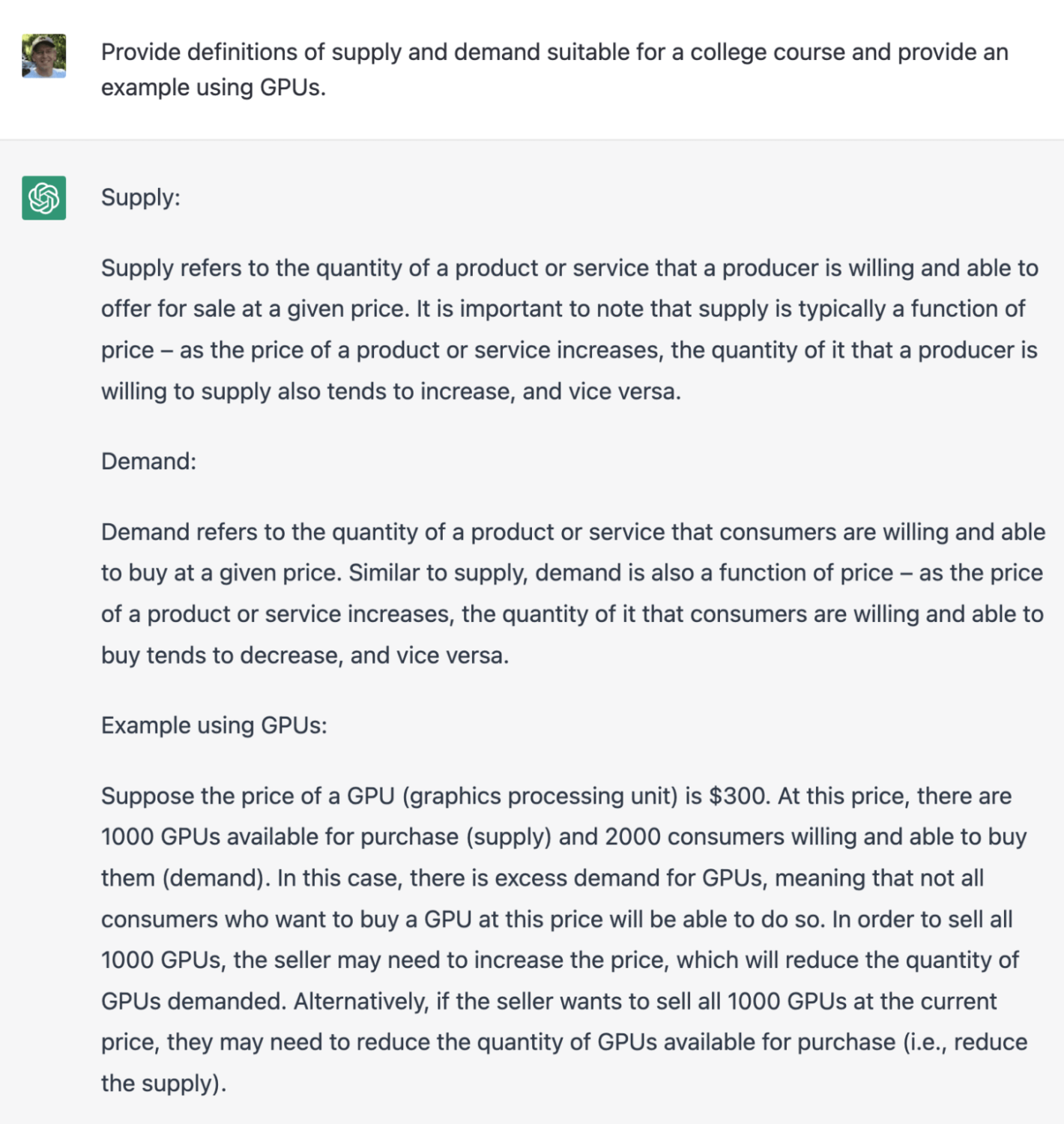
Điều đó không hoàn toàn đúng, nhưng sẽ nhanh hơn nhiều nếu đưa lời nhắc vào ChatGPT rồi chỉnh sửa đầu ra để làm cho nó chính xác hơn là viết từ đầu. Và tôi nghĩ rằng đây sẽ luôn là cách để nghĩ về những công cụ này – vô cùng hữu ích để tạo bản thảo đầu tiên cho con người sau đó xem xét, bổ sung và chỉnh sửa.
Nhưng LLM không chỉ giúp các doanh nghiệp vừa và nhỏ – họ còn có thể cung cấp cho các nhà thiết kế hướng dẫn bản thảo đầu tiên của một số công việc họ làm. Hãy tưởng tượng bạn là một nhà thiết kế hướng dẫn được ghép đôi với một giảng viên để tạo ra một khóa học về kinh tế vi mô. Những công cụ này có thể giúp bạn nhanh chóng tạo bản thảo đầu tiên của:
Kết quả học tập

Lời nhắc thảo luận và phiếu tự đánh giá

Các hạng mục đánh giá quá trình

Một lần nữa, không hoàn toàn đúng, nhưng là điểm khởi đầu vô cùng hữu ích. Đặc biệt nếu bạn cần tạo ra hàng nghìn mục đánh giá.
Như chúng ta thấy ở trên, LLM có thể tham gia ở cấp độ cơ bản với các khái niệm từ lĩnh vực thiết kế hướng dẫn như câu hỏi thảo luận, phiếu tự đánh giá, câu hỏi trắc nghiệm và phản hồi. Nhưng theo cùng một cách mà một SME trong một chuyên ngành cần kiểm tra bản thảo tài nguyên thông tin về độ chính xác của thông tin, một nhà thiết kế hướng dẫn sẽ cần kiểm tra các tài nguyên giáo dục đó về độ chính xác về mặt sư phạm và tâm lý. Và chắc chắn cần phải thực hiện các cải tiến.
Tôi đã đề cập đến Cơ sở hạ tầng nội dung này sẽ là mở chưa?
Trong đơn đăng ký tác phẩm do mình tạo ra bằng phần mềm AI như Stable Diffusion, Steven Thaler đã viết rằng tác phẩm "được tạo ra một cách tự động bởi một thuật toán máy tính chạy trên máy" và rằng ông "đang tìm cách đăng ký tác phẩm do máy tính tạo ra này dưới dạng tác phẩm thuê cho chủ sở hữu". Nói cách khác, ông đã nộp đơn xin bảo vệ bản quyền cho tác phẩm do mình tạo ra bằng cách cung cấp lời nhắc cho một công cụ AI tạo ra. Văn phòng Bản quyền Hoa Kỳ đã từ chối nỗ lực đăng ký bản quyền tác phẩm của ông - hai lần. Trong phản hồi cuối cùng của họ, họ đã viết:
Luật bản quyền chỉ bảo vệ “thành quả lao động trí tuệ” “được xây dựng trên sức mạnh sáng tạo của trí óc [con người]”. COMPENDIUM (THIRD) § 306 (trích dẫn Vụ án nhãn hiệu, 100 U.S. 82, 94 (1879)); xem thêm COMPENDIUM (THIRD) § 313.2 (Văn phòng sẽ không đăng ký các tác phẩm “do máy móc hoặc quy trình cơ học đơn thuần tạo ra” hoạt động “mà không có bất kỳ sự tham gia hoặc can thiệp sáng tạo nào từ tác giả là con người” vì theo luật định, “một tác phẩm phải do con người tạo ra”)….
Mặc dù Hội đồng [xem xét] không biết đến một tòa án Hoa Kỳ nào đã xem xét liệu trí tuệ nhân tạo có thể là tác giả cho mục đích bản quyền hay không, nhưng các tòa án đã nhất quán khi nhận thấy rằng biểu hiện không phải của con người không đủ điều kiện để được bảo vệ bản quyền….
Các tòa án giải thích Đạo luật bản quyền, bao gồm Tòa án tối cao, đã thống nhất giới hạn bảo vệ bản quyền đối với các sáng tạo của tác giả là con người…. Vì lý do này, Sổ tay thực hành của Văn phòng Bản quyền Hoa Kỳ — sổ tay thực hành của Văn phòng — từ lâu đã yêu cầu tác giả là con người để đăng ký…. Vì luật bản quyền được quy định trong Đạo luật năm 1976 yêu cầu tác giả là con người nên Tác phẩm không thể được đăng ký.
Nói cách khác, theo Văn phòng Bản quyền Hoa Kỳ, đầu ra từ các chương trình như ChatGPT hoặc Stable Diffusion không đủ điều kiện để được bảo vệ bản quyền. Bây giờ, điều đó có thể thay đổi nếu Quốc hội can thiệp (họ thực sự có khả năng làm bất cứ điều gì không?), hoặc nếu Tòa án Tối cao quay lưng lại với tiền lệ trong nhiều thập kỷ (điều này, phải thừa nhận là đã xảy ra gần đây). Nhưng trừ khi có điều gì đó khá nghiêm trọng xảy ra theo hướng này, đầu ra của các chương trình AI tạo sinh sẽ tiếp tục được chuyển ngay vào phạm vi công cộng. Do đó, chúng sẽ là các nguồn tài nguyên giáo dục mở theo định nghĩa chung:
Tài nguyên giáo dục mở (OER) là các tài liệu giảng dạy, học tập và nghiên cứu (1) thuộc phạm vi công cộng hoặc (2) được cấp phép theo cách cung cấp cho mọi người quyền tự do và vĩnh viễn để tham gia vào các hoạt động 5R.
Các công cụ AI tạo sinh có thể có tác động đáng kinh ngạc đến độ rộng và sự đa dạng của OER hiện có, vì chúng sẽ giảm đáng kể chi phí và thời gian cần thiết để tạo ra các nguồn thông tin làm nền tảng cho các tài liệu học tập này. Nguồn tài trợ hiện tại cho việc tạo ra OER (nếu có) thường tập trung vào các khóa học có số lượng sinh viên tuyển sinh lớn nhất. Điều này có ý nghĩa khi lý thuyết từ thiện của bạn là số tiền bạn chi tiêu phải mang lại lợi ích cho nhiều người nhất có thể. Nhưng lý thuyết từ thiện đó cũng có nghĩa là "phần đuôi dài" của các khóa học mà mỗi khóa học chỉ tuyển sinh tương đối ít sinh viên thì khó có thể nhận được tài trợ. LLM sẽ thay đổi hoàn toàn nền kinh tế của việc tạo ra OER và cũng sẽ giúp OER có thể đến với các khóa học này. (Và trong khi LLM sẽ có tác động đáng kể đến nền kinh tế của việc tạo ra OER, thì chúng có thể không có tác động đáng kể đến tính bền vững, duy trì và bảo dưỡng OER theo thời gian.)
Hai câu hỏi có thể thú vị: Thứ nhất, cũng giống như cách giáo viên lo lắng về việc học sinh nộp bài do LLM viết, vấn đề tương tự cũng đang xảy ra với Văn phòng Bản quyền Hoa Kỳ. Nếu kết quả của những công cụ này không đủ điều kiện để được bảo vệ, Văn phòng sẽ sớm có mối quan tâm sâu sắc trong việc tìm hiểu tác phẩm nào được tạo ra bởi máy móc và tác phẩm nào thực sự là kết quả của sự sáng tạo của con người.
Thứ hai, cần phải đầu tư bao nhiêu thời gian và công sức để cải thiện các bản thảo do một trong những công cụ này tạo ra trước khi phiên bản cải tiến được công nhận là tác phẩm phái sinh đủ điều kiện để được bảo vệ bản quyền? (Hãy nghĩ về Pride and Prejudice and Zombies. Mặc dù dựa trên một tác phẩm thuộc phạm vi công cộng, nhưng nó đã được chuyển đổi đủ để xứng đáng được bảo vệ bản quyền riêng.)
Tác động đến các Nhà xuất bản truyền thống và OER
Tôi đã từng viết rằng những người ủng hộ OER cuối cùng sẽ phải hối tiếc vì họ chỉ dựa vào việc tiết kiệm chi phí để ủng hộ, vì giá của các tài liệu học tập độc quyền sẽ giảm xuống và quan điểm đó sẽ biến mất:
[Mặc dù] chi phí của các tài liệu giáo dục có bản quyền theo truyền thống trước đây cao hơn nhiều so với giá của OER, nhưng chi phí của sách giáo khoa đã đi ngang lần đầu tiên sau nhiều thập kỷ (Perry 2020). Khi các nhà xuất bản phản ứng với áp lực giá do OER tạo ra trên thị trường tài liệu khóa học, thì sự khác biệt về giá của OER và các nguồn tài nguyên có bản quyền theo truyền thống có khả năng sẽ tiếp tục giảm. Nếu giả thuyết về khả năng tiếp cận là đúng, tác động của OER đối với kết quả của sinh viên do khả năng chi trả sẽ giảm song song. Nói cách khác, việc áp dụng OER có thể không phải là chiến lược dài hạn để tiết kiệm cho sinh viên một khoản tiền đáng kể hoặc thu hẹp khoảng cách thành tích giữa sinh viên có thu nhập thấp và sinh viên có thu nhập cao. (2021)
Tác động của LLM đối với nền kinh tế của việc tạo ra các tài liệu độc quyền phải giống như đối với OER (giả sử nhà xuất bản thích nghi với thực tế mới này). Khi "các tác giả tên tuổi" bị thay thế bởi "các biên tập viên tên tuổi" của tác phẩm ban đầu do LLM soạn thảo, số tiền bản quyền mà các nhà xuất bản nợ tác giả sẽ giảm đáng kể hoặc thậm chí có thể biến mất hoàn toàn. Giờ đây, có thể sản xuất và bán tài liệu độc quyền với chi phí rẻ hơn nhiều so với trước đây, các nhà xuất bản có thể chuyển khoản tiết kiệm này cho sinh viên để cạnh tranh hiệu quả hơn với giá của OER hoặc chỉ cần sử dụng khoản tiết kiệm này để cải thiện biên lợi nhuận của họ hoặc một chút cả hai. Điểm mấu chốt ở đây là lợi ích của LLM đối với việc sản xuất tài liệu học tập KHÔNG chỉ dành riêng cho OER. Trên thực tế, lợi ích có thể tích lũy không cân xứng cho các nhà xuất bản tài liệu độc quyền vì các nhà xuất bản OER chưa bao giờ phải trả tiền bản quyền. LLM có thể đưa tài liệu độc quyền ngang bằng với OER về mặt này.
Thời đại của nhà thiết kế hướng dẫn
Chúng tôi đã nói trong hơn một thập kỷ rằng nội dung là một mặt hàng. Điều đó đúng hơn bao giờ hết trong bối cảnh của LLM. Nếu nội dung không phân biệt tài liệu học tập với nhau, thì điều gì sẽ làm được? Có thể cuối cùng chúng ta sẽ đạt đến thời điểm mà hiệu quả sẽ trở thành yếu tố hàng đầu như sự khác biệt chính giữa các tài liệu học tập. Và trong khi độ chính xác của nội dung là lĩnh vực của các doanh nghiệp vừa và nhỏ, thì hiệu quả trong việc hỗ trợ học tập là lĩnh vực của các nhà thiết kế hướng dẫn.
Khi vai trò của các doanh nghiệp vừa và nhỏ thay đổi từ tác giả sang biên tập viên và thời gian cam kết của họ cho các dự án giảm đi, thì vai trò của các nhà thiết kế hướng dẫn sẽ ngày càng quan trọng và nỗ lực hơn. Nhà thiết kế hướng dẫn có khả năng là kỹ sư nhắc chính. Chuyên môn thiết kế hướng dẫn sẽ được phản ánh trong đầu ra của các hệ thống này theo tỷ lệ với mức độ chuyên môn thiết kế hướng dẫn được nhúng vào các lời nhắc được đưa vào hệ thống.
Các nhà thiết kế hướng dẫn - ID (Instructional Designer) sẽ thiết kế lời nhắc và đưa chúng vào hệ thống, sau đó thực hiện các vòng đánh giá nhanh đầu ra với các SME tại mỗi bước trong quy trình từ đầu (điều gì còn thiếu trong danh sách kết quả học tập này?) cho đến cuối (phản hồi về mục đánh giá hình thành này có chính xác sửa lỗi hiểu lầm mà học sinh có thể mắc phải khi họ chọn tùy chọn B không?). Vì độ chính xác đang được đảm bảo thông qua quy trình này, nên cần áp dụng một lượng lớn chuyên môn về thiết kế hướng dẫn vào các đầu ra khác nhau của các hệ thống này để kết hợp chúng lại với nhau theo cách gắn kết, mạch lạc, hỗ trợ hiệu quả cho việc học. Một lần nữa, cách đúng đắn để nghĩ về những công cụ này là chúng cực kỳ hữu ích trong việc tạo bản thảo đầu tiên để con người sau đó xem xét, bổ sung và chỉnh sửa. Và khi nói đến việc tạo ra các tài liệu học tập có hiệu quả cao cho tất cả người học, sẽ có rất nhiều việc bổ sung và chỉnh sửa cần thực hiện.
Thật là thời điểm tuyệt vời để trở thành nhà thiết kế hướng dẫn! Mọi trường dạy thiết kế hướng dẫn cần phải cập nhật ngay chương trình giảng dạy của mình để tận dụng sự tồn tại của các công cụ này. Sử dụng LLM và AI khác một cách hiệu quả (ví dụ: tạo hình ảnh tùy chỉnh) sẽ là một phần quan trọng trong việc chuẩn bị cho các nhà thiết kế hướng dẫn trong thập kỷ tới – một thập kỷ có vẻ là thời điểm tuyệt vời để trở thành nhà thiết kế hướng dẫn!
Chủng loại artificial intelligence, instructional design, open content, sustainability
2022 saw some significant advancements in artificial intelligence. My threshold for “significant” here being that the advances moved out of labs and arXiv.org preprints and into tools that many people were using and talking about. Lots of people thought text-to-image tools like DALL-E, Stable Diffusion, and Midjourney were fun. But Large Language Models (LLMs), and particularly the recent demo of ChatGPT, seem to have put the fear of God into everyone from middle school English teachers to the CEO of Google. The potential partnership between OpenAI (the makers of ChatGPT) and Microsoft may even present the first substantive challenge to Google’s search monopoly we’ve ever seen – and that’s saying something. While most of the dialog around AI and education seems to be focused on assessment, I think the implications for instructional designers are critically important, too. And, because you’ve got to play the hits, let’s look at what their impact will be on OER as well.
About Instructional Designers
I think a lot of people believe that instructional designers are the people who are really good at using the campus LMS – folks who can create new course shells for faculty, help faculty get their content uploaded into the LMS, and maybe even help with a little multimedia editing and production. Unfortunately, literally none of those things are instructional design. Instructional design is the process of leveraging what we understand about how people learn to create experiences that maximize the likelihood that the people who participate in those experiences will learn. Instructional designers need a deep understanding of both learning science research and educational technologies in order to effectively integrate them in support of learning. Uploading a syllabus PDF into Blackboard is not instructional design.
You know what else isn’t instructional design? The creation of accurate descriptions and explanations of facts, theories, and models. The raw text and images that make up the overwhelming majority of what we call textbooks. I’ve written previously about the difference between informational resources and educational resources. Wikipedia and other encyclopedias are informational resources. Reference materials and technical documentation are informational resources. The overwhelming majority of textbooks are primarily informational resources. What distinguishes an educational resource from an informational resource is that the latter shows some intentional application of knowledge about how people learn. I have previously argued that the minimum amount of effort you could invest to convert an informational resource into an educational resource was to add practice with feedback. That simple sounding task quickly explodes in complexity as you consider the research on what form that practice should take, how long it should last, when it should be scheduled, what kind of feedback should be provided, whether the feedback should come immediately or after some delay, etc.
Now, please don’t misunderstand me – there is absolutely an art and science to creating accurate, beautiful informational resources. It’s just a different art and science from the one involved in creating educational resources. All educational resources begin as informational resources, so they are critically important to the work we do as instructional designers. You might say they are a kind of intellectual infrastructure, in the way Brett Frischmann uses the term:
Intellectual infrastructure, such as basic research, ideas, general purpose technologies, and languages, creates benefits for society primarily by facilitating a wide range of downstream productive activities, including information production, innovation, and the development of products and services, as well as education, community building and interaction, democratic participation, socialization, and many other socially valuable activities. (emphasis added)
Informational resources (especially openly licensed ones) facilitate a wide range of downstream productive activities, including the creation of educational resources. Or, to use language I have used often before, informational resources are “content infrastructure” upon which instructional designers build when they create educational resources.
LLMs Will Make Creating the Content Infrastructure Significantly Easier, Faster, and Cheaper
LLMs will dramatically increase the speed of creating the informational resources that comprise the content infrastructure. Of course the drafts of these informational resources will need to be reviewed and improvements will need to be made – just as is the case with all first drafts – to insure accuracy and timeliness. But it appears that LLMs can get us 80% or so of the way to reasonable first drafts orders of magnitude faster, eliminating the majority of the expense involved in this part of the process. Here’s an example of what I’m talking about. Imagine you’re a SME who has been tasked with writing the content for an introductory economics textbook. (The following examples are from ChatGPT.)
Definitions and Examples
That’s not quite right, but it’s far faster to feed a prompt into ChatGPT and then edit the output to make it accurate than it would be to write that from scratch. And I think this will always be the way to think about these tools – incredibly helpful for creating first drafts for humans to then review, augment, and polish.
But LLMs won’t just help SMEs – they can also provide instructional designers with first drafts of some of the work they do. Imagine you’re an instructional designer who’s been paired with a faculty member to create a course in microeconomics. These tools might help you quickly create first drafts of:
Learning Outcomes
Discussion Prompts and Rubrics
Formative Assessment Items
Again, not exactly right, but an incredibly helpful starting point. Especially if you need to create several thousand assessment items.
As we see above, LLMs can engage at a basic level with concepts from the instructional design domain like discussion questions, rubrics, multiple choice questions, and feedback. But in the same way that a SME in a discipline needs to check a draft informational resource for accuracy of information, an instructional designer will need to check these educational resources for pedagogical and psychometric accuracy. And improvements will absolutely need to be made.
Did I Mention this Content Infrastructure Will Be Open?
In his application to register a work he created using AI software like Stable Diffusion, Steven Thaler wrote that the work “was autonomously created by a computer algorithm running on a machine” and that he was “seeking to register this computer-generated work as a work-for-hire to the owner.” In other words, he applied for copyright protection for a work he created by providing a prompt to a generative AI tool. The US Copyright Office rejected his attempt to register copyright in the work – twice. In their final response they wrote:
Copyright law only protects “the fruits of intellectual labor” that “are founded in the creative powers of the [human] mind.” COMPENDIUM (THIRD) § 306 (quoting Trade-Mark Cases, 100 U.S. 82, 94 (1879)); see also COMPENDIUM (THIRD) § 313.2 (the Office will not register works “produced by a machine or mere mechanical process” that operates “without any creative input or intervention from a human author” because, under the statute, “a work must be created by a human being”)….
While the [review] Board is not aware of a United States court that has considered whether artificial intelligence can be the author for copyright purposes, the courts have been consistent in finding that non-human expression is ineligible for copyright protection….
Courts interpreting the Copyright Act, including the Supreme Court, have uniformly limited copyright protection to creations of human authors…. For this reason, the Compendium of U.S. Copyright Office Practices — the practice manual for the Office — has long mandated human authorship for registration…. Because copyright law as codified in the 1976 Act requires human authorship, the Work cannot be registered.
In other words, as far as the US Copyright Office is concerned, output from programs like ChatGPT or Stable Diffusion are not eligible for copyright protection. Now, that could change if Congress gets involved (are they actually capable of doing anything?), or if the Supreme Court turned its collective back on decades of precedent (which, admittedly, has been happening recently). But unless something rather dramatic happens along these lines, the outputs of generative AI programs will continue to pass immediately into the public domain. Consequently, they will be open educational resources under the common definition:
Open educational resources (OER) are teaching, learning, and research materials that are either (1) in the public domain or (2) licensed in a manner that provides everyone with free and perpetual permission to engage in the 5R activities.
Generative AI tools could have an incredible impact on the breadth and diversity of OER that exist, since they will dramatically decrease the cost and time necessary to create the informational resources that underlie these learning materials. Current funding for the creation of OER (when it’s available at all) typically focuses on the courses enrolling the largest number of students. This makes sense when your theory of philanthropy is that the money you spend should benefit the most people possible. But that theory of philanthropy also means that the “long tail” of courses that each enroll relatively few students are unlikely to ever receive funding. LLMs will radically alter the economics of creating OER, and should make it possible for OER to come to these courses as well. (And while LLMs will have a significant impact on the economics of creating OER, they may not have as dramatic an impact on the sustainability, maintenance, and upkeep of OER over time.)
Two potentially interesting questions: First, in the same way teachers are worried about students submitting work written by LLMs, the same issue is coming for the US Copyright Office. If the output of these tools are not eligible for protection, the Office will soon have a deep interest in understanding which works are created by machines and which are truly the result of human creativity.
Second, how much time and effort would need to be invested in improving the drafts created by one of these tools before the improved version would be recognized as a derivative work that is eligible for copyright protection? (Think about Pride and Prejudice and Zombies. While it was based on a public domain work, it was transformed sufficiently to deserve its own copyright protection.)
The Impact on Traditional Publishers and OER
I’ve written before that OER advocates would eventually be sorry that they based their advocacy almost exclusively on cost savings, because the price of proprietary learning materials will come down and that talking point will evaporate:
[While] the cost of traditionally copyrighted educational materials has historically been much higher than the price of OER, the cost of textbooks has plateaued for the first time in decades (Perry 2020). As publishers respond to the price pressure created by OER in the course materials market, the difference in the prices of OER and traditionally copyrighted resources is likely to continue to decrease. If the access hypothesis holds, the impact of OER on student outcomes attributable to affordability will decrease in parallel. In other words, adopting OER may not be a long-term strategy for saving students significant amounts of money or closing the achievement gap between lower income and higher income students. (2021)
The impact of LLMs on the economics of creating proprietary materials should be the same as it is for OER (assuming publisher adapt to this new reality). As “big name authors” become supplanted by “big name editors” of work initially drafted by LLMs, the amount of royalties publishers owe to authors will either decrease significantly or may even disappear altogether. Now able to produce and sell proprietary material much less expensively than they were in the past, publishers could either pass this savings on to students in order to compete even more effectively with the price of OER, or simply use the savings to improve their margins, or a little of both. The key point here is that the boon of LLMs for learning materials production is NOT exclusive to OER. In fact, the benefit may accrue disproportionately to publishers of proprietary materials since the publishers of OER have never had to pay royalties. LLMs may put proprietary materials on equal footing with OER in this regard.
The Age of the Instructional Designer
We’ve been saying for more than a decade that content is a commodity. That is more true in the context of LLMs than it ever has been before. If content doesn’t differentiate learning materials from one another, what will? It’s possible we may finally be reaching a time when effectiveness will come to the forefront as the primary difference between learning materials. And while content accuracy is the domain of SMEs, effectiveness at supporting learning is the domain of instructional designers.
As the role of SMEs changes from author to editor and their time commitment to projects decreases, the role of instructional designers will grow in importance and effort. The instructional designer is likely the primary prompt engineer. Instructional design expertise will be reflected in the output of these systems in proportion to the degree that instructional design expertise is embedded in the prompts fed into the systems. IDs will engineer prompts and feed them into systems and then do rounds of rapid review of outputs with SMEs at each step in the process from the beginning (what is missing from this list of learning outcomes?) to the end (does the feedback on this formative assessment item accurately correct the misunderstanding a student likely has when they select option B?). As accuracy is being assured via this process, a significant amount of instructional design expertise will need to be applied to the varied outputs of these systems to bring them together in a cohesive, coherent way that will effectively support learning. Again, the right way to think about these tools is that they are incredibly helpful for creating first drafts for humans to then review, augment, and polish. And, when it comes to creating learning materials that are highly effective for all learners, there will be plenty of augmenting and polishing to do.
What an incredible time to be an instructional designer! Every school that teaches instructional design needs to immediately update their curriculum to leverage the existence of these tools. Using LLMs and other AI effectively (e.g., creating custom images) will be a key part of preparing instructional designers for the next decade – a decade that looks to be an absolutely incredible time to be an instructional designer!
Categories artificial intelligence, instructional design, open content, sustainability
Dịch: Lê Trung Nghĩa
letrungnghia.foss@gmail.com
Tác giả: Nghĩa Lê Trung
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Blog này được chuyển đổi từ http://blog.yahoo.com/letrungnghia trên Yahoo Blog sang sử dụng NukeViet sau khi Yahoo Blog đóng cửa tại Việt Nam ngày 17/01/2013.Kể từ ngày 07/02/2013, thông tin trên Blog được cập nhật tiếp tục trở lại với sự hỗ trợ kỹ thuật và đặt chỗ hosting của nhóm phát triển...
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
 ‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
 Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
 12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
 Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
 Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 ‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
 Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Tài nguyên Giáo dục Mở trong kỷ nguyên AI
 cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
 Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
 Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025
Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025
 Tập huấn về Tài nguyên Giáo dục Mở trong Tọa đàm và Đào tạo chuyển đổi số và AI tại Trường Du lịch - Đại học Huế, 08/08/2025
Tập huấn về Tài nguyên Giáo dục Mở trong Tọa đàm và Đào tạo chuyển đổi số và AI tại Trường Du lịch - Đại học Huế, 08/08/2025

