 Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam
Blog FOSS by Lê Trung Nghĩa
Phần mềm tự do nguồn mở cho Việt Nam

Sketching the data flow and determining responsibility in a data situation related to personal data protection - experiences from UK’s Anonymisation Decision-making Framework


***
Tóm tắt: Phác thảo luồng dữ liệu và xác định trách nhiệm trong một tình huống dữ liệu liên quan tới bảo vệ dữ liệu cá nhân là một trong những công việc đầu tiên và không thể thiếu trong quá trình kiểm tra tình huống dữ liệu trước khi xác định liệu có rủi ro tiết lộ dữ liệu nào cần phải giải quyết trong phạm vi trách nhiệm đó hay không, cũng như mức độ nhạy cảm của tình huống dữ liệu đó. Bài viết cho thấy Khung ra quyết định ẩn danh (ADF) của Vương quốc Anh thực hiện điều đó như thế nào và đưa ra một số gợi ý.
Các từ khóa: dữ liệu và môi trường, khung ra quyết định ẩn danh, người kiểm soát dữ liệu và người xử lý dữ liệu, tình huống dữ liệu, vai trò và trách nhiệm
Abstract: Sketching the data flow and determining responsibility in a data situation related to personal data protection is the one of the first and indispensable steps in the data situation audit before determining whether there is any risk of data disclosure needs to be resolved within the scope of that responsibility, as well as the sensitivity of the data situation. The article shows how the UK's Anonymous Decision Framework (ADF) does that and gives some suggestions.
Keywords: data and environment, anonymisation decision-making framework, data controller and data processor, data situations, roles and responsibilities
***
Ngày 17/04/2023, chính phủ đã ban hành Nghị định số 13/2023/NĐ-CP[1] (Sau đây gọi tắt là NĐ13) về ‘Bảo vệ dữ liệu cá nhân’, có hiệu lực thi hành từ 01/07/2023.
Triển khai thực hiện NĐ13, tất cả các bên liên quan, bao gồm các bên: kiểm soát dữ liệu cá nhân; xử lý dữ liệu cá nhân; kiểm soát và xử lý dữ liệu cá nhân; bên thứ ba, chắc chắn sẽ có việc phải phác thảo luồng dữ liệu và xác định trách nhiệm của mình trong bất kỳ tình huống dữ liệu nào có liên quan tới bảo vệ dữ liệu cá nhân. Về việc này, kinh nghiệm của các quốc gia đi trước có thể giúp chúng ta học hỏi được nhiều điều. Dưới đây trình bày cách để giúp phác thảo luồng dữ liệu và xác định trách nhiệm của tổ chức đối với một tình huống dữ liệu bằng việc sử dụng Khung ra quyết định ẩn danh của Vương quốc Anh[2] (sau đây gọi là Khung ADF) để có thể tuân thủ với các nội dung của ‘Quy định bảo vệ dữ liệu chung’ - GDPR[3] (General Data Protection Regulation) của Liên minh châu Âu ngày 27/04/2016, một Quy định với mục đích tương tự như NĐ13 của Việt Nam, có hiệu lực đối với tất cả các quốc gia thành viên của Liên minh châu Âu và đã được áp dụng vào thực tế từ ngày 25/05/2018.
Khung ADF có 10 thành phần (Hình 1), trong đó thành phần 2 của nó sử dụng để thực hiện việc phác thảo luồng dữ liệu và xác định trách nhiệm của bạn/tổ chức của bạn. Cùng với thành phần 1 (Mô tả/nắm bắt vấn đề trình bày), nó giúp trả lời cho câu hỏi: Bạn/tổ chức của bạn có trách nhiệm gì, một mình hay chung với (các) tổ chức khác, về một tình huống dữ liệu?
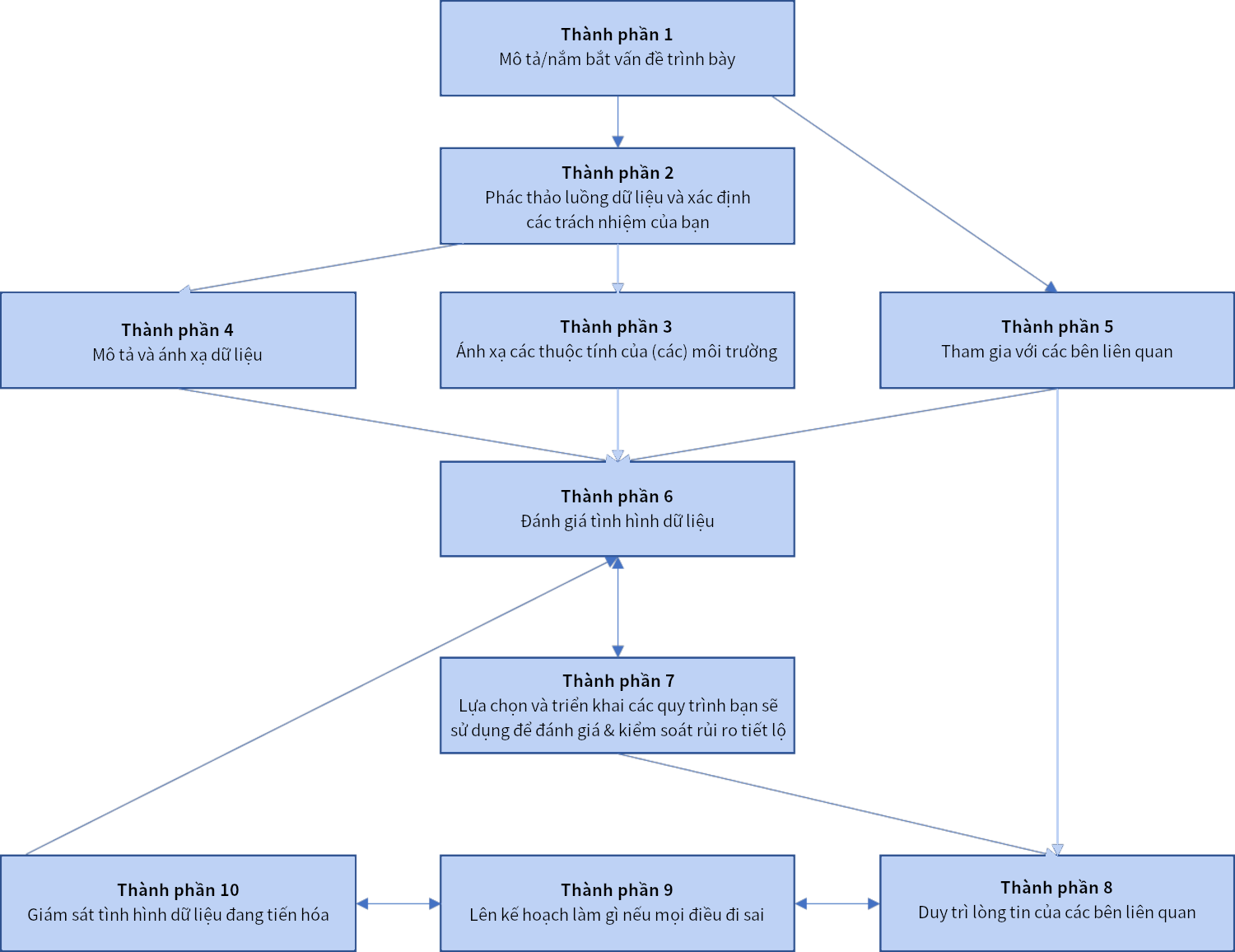
Hình 1. Khung ADF của Vương quốc Anh
Để giải thích vì sao, chúng ta cần xem xét các trách nhiệm đó được chỉ định như thế nào trong NĐ13. NĐ13 đưa ra mô tả các dạng vai trò xử lý dữ liệu cá nhân sau:
Bên Kiểm soát dữ liệu cá nhân là tổ chức, cá nhân quyết định mục đích và phương tiện xử lý dữ liệu cá nhân.
Bên Xử lý dữ liệu cá nhân là tổ chức, cá nhân thực hiện việc xử lý dữ liệu thay mặt cho Bên Kiểm soát dữ liệu, thông qua một hợp đồng hoặc thỏa thuận với Bên Kiểm soát dữ liệu.
Bên Kiểm soát và xử lý dữ liệu cá nhân là tổ chức, cá nhân đồng thời quyết định mục đích, phương tiện và trực tiếp xử lý dữ liệu cá nhân.
Bên thứ ba là tổ chức, cá nhân ngoài Chủ thể dữ liệu, Bên Kiểm soát dữ liệu cá nhân, Bên Xử lý dữ liệu cá nhân, Bên Kiểm soát và xử lý dữ liệu cá nhân được phép xử lý dữ liệu cá nhân.
Từ bốn dạng nêu trên, có thể thấy chỉ có hai vai trò chính trong bảo vệ dữ liệu cá nhân, đó là: (1) Kiểm soát dữ liệu cá nhân; và (2) Xử lý dữ liệu cá nhân. Theo NĐ13, sự khác biệt cơ bản giữa 2 vai trò này nằm ở chỗ: Bên Kiểm soát dữ liệu cá nhân là bên đưa ra quyết định cả mục đích và phương tiện xử lý dữ liệu cá nhân, trong khi Bên Xử lý dữ liệu cá nhân KHÔNG là bên đưa ra quyết định về mục đích và phương tiện, mà chỉ “thực hiện việc xử lý dữ liệu thay mặt cho Bên Kiểm soát dữ liệu, thông qua một hợp đồng hoặc thỏa thuận với Bên Kiểm soát dữ liệu”. Xác định được rõ vai trò của các bên sẽ giúp xác định rõ được trách nhiệm của họ.
Trong thực tế triển khai NĐ13, một trường hợp khác có thể xảy ra là khi hai tổ chức có thể hành động cùng nhau như là các Bên Kiểm soát chung dữ liệu cá nhân thông qua một thỏa thuận/hợp đồng giữa hai bên - trường hợp này cần minh bạch đặt ra các vai trò và trách nhiệm nào được đồng thuận cho việc tuân thủ NĐ13 cho từng tổ chức/cá nhân.
Bất kỳ tổ chức/các nhân nào khác không nằm trong hai vai trò ở trên được phân loại như là ‘Người sử dụng dữ liệu’.
Dựa vào cách tiếp cận ở trên, có thể xây dựng bảng dưới đây:
Bảng 1. Cần xem xét điều gì khi xác định trách nhiệm của bạn
|
|
Bên/Người kiểm soát dữ liệu (NKS) |
Bên/Người xử lý dữ liệu (NXL) |
Bên/Người sử dụng (NSD) (không là NKS/NXL) |
|
Vai trò |
Xác định mục đích và phương tiện của việc xử lý. NKS có thể có trách nhiệm một mình hoặc chung với người khác. |
Hành động thay mặt (theo đường hướng) của NKS. Có thể có sự tự chủ nhất định về các phương tiện xử lý. |
Không có vai trò xác định mục đích hoặc các phương tiện xử lý dữ liệu cá nhân. |
|
Nguồn gốc |
NKS có thể thu thập dữ liệu, chỉ đạo việc thu thập dữ liệu hoặc bắt buộc chia sẻ dữ liệu theo yêu cầu luật định. Điều này ngụ ý nguồn gốc của dữ liệu có thể là Môi trường Dữ liệu (MTDL) của riêng NKS hoặc MTDL ngược lên trên từ họ. |
NXL có thể thu thập dữ liệu nhân danh một NKS hoặc có dữ liệu được chia sẻ với nó theo chỉ thị của NKS. Điều này ngụ ý là gốc của dữ liệu có thể là MTDL của riêng NXL hoặc (nhiều) MTDL ngược lên trên. |
Được NKS hoặc NXL cung cấp với quyền truy cập tới dữ liệu ẩn danh theo chức năng (dựa vào sự chỉ đạo của NKS). |
|
Dạng dữ liệu |
Bạn vẫn có thể là một NKS ngay cả nếu bạn không có quyền truy cập tới dữ liệu cá nhân. Tuy nhiên, thông thường, NKS nắm giữ các phương tiện để xác định các chủ thể dữ liệu. Việc triển khai các biện pháp kỹ thuật và tổ chức có thể liên quan (trong số những điều khác) tới việc duy trì xác định trực tiếp thông tin (thường được tham chiếu tới như là các khóa) và dữ liệu thuộc tính tách biệt nhau. Nếu NKS phá hủy các khóa đó đối với một tập hợp dữ liệu, thì câu hỏi liệu dữ liệu đó có còn là cá nhân hay thông tin ẩn danh hay không có thể cần phải đánh giá đúng thông qua kiểm tra tình huống dữ liệu. Không nên cho rằng nếu các khóa bị phá hủy thì dữ liệu không còn nhận dạng được nữa. |
Dữ liệu đối với NXL có thể là nhận dạng được (hoặc trực tiếp hoặc gián tiếp) và vì thế được phân loại như là dữ liệu cá nhân. Đối với dữ liệu được lưu giữ mang tính chất nhận dạng gián tiếp, rủi ro nhận dạng có thể đã được giảm thiểu sao cho rủi ro nhận dạng lại được coi là rất thấp nhưng trên mức không đáng kể, thì dữ liệu đó vẫn được phân loại là dữ liệu cá nhân.
|
Đối với người nhận dữ liệu được coi là NSD, dữ liệu đó phải được ẩn danh theo chức năng. Điều này có thể đạt được hoặc qua các hạn chế đối với dữ liệu hoặc các hạn chế đối với sự kết hợp của dữ liệu đó với môi trường. |
Khung ADF sử dụng thuật ngữ ‘tình huống dữ liệu’ và định nghĩa nó là tập hợp tổng hợp các mối quan hệ giữa một số dữ liệu và tập hợp các môi trường của chúng. Ví dụ: bản thân tổ chức của bạn sẽ tạo thành một môi trường, trong khi mọi chia sẻ hoặc phổ biến dữ liệu được đề xuất sẽ tạo thành một môi trường khác. Mỗi môi trường sẽ có cấu hình khác nhau với các tính năng cốt lõi giống nhau: con người, dữ liệu khác, cơ sở hạ tầng và quy trình quản trị.
Tình huống dữ liệu có thể tĩnh hoặc động. Tình huống dữ liệu tĩnh là khi không có sự di chuyển dữ liệu giữa các môi trường; tình huống dữ liệu động là nơi có sự chuyển động như vậy. Theo định nghĩa, tất cả các quá trình chia sẻ hoặc phổ biến dữ liệu diễn ra trong các tình huống dữ liệu động trong đó dữ liệu được di chuyển có chủ ý từ môi trường này sang môi trường khác. Một tình huống dữ liệu động có thể tương đối đơn giản liên quan đến việc di chuyển dữ liệu từ môi trường này sang môi trường khác. Tuy nhiên, thông thường nó phức tạp hơn, liên quan đến nhiều môi trường.
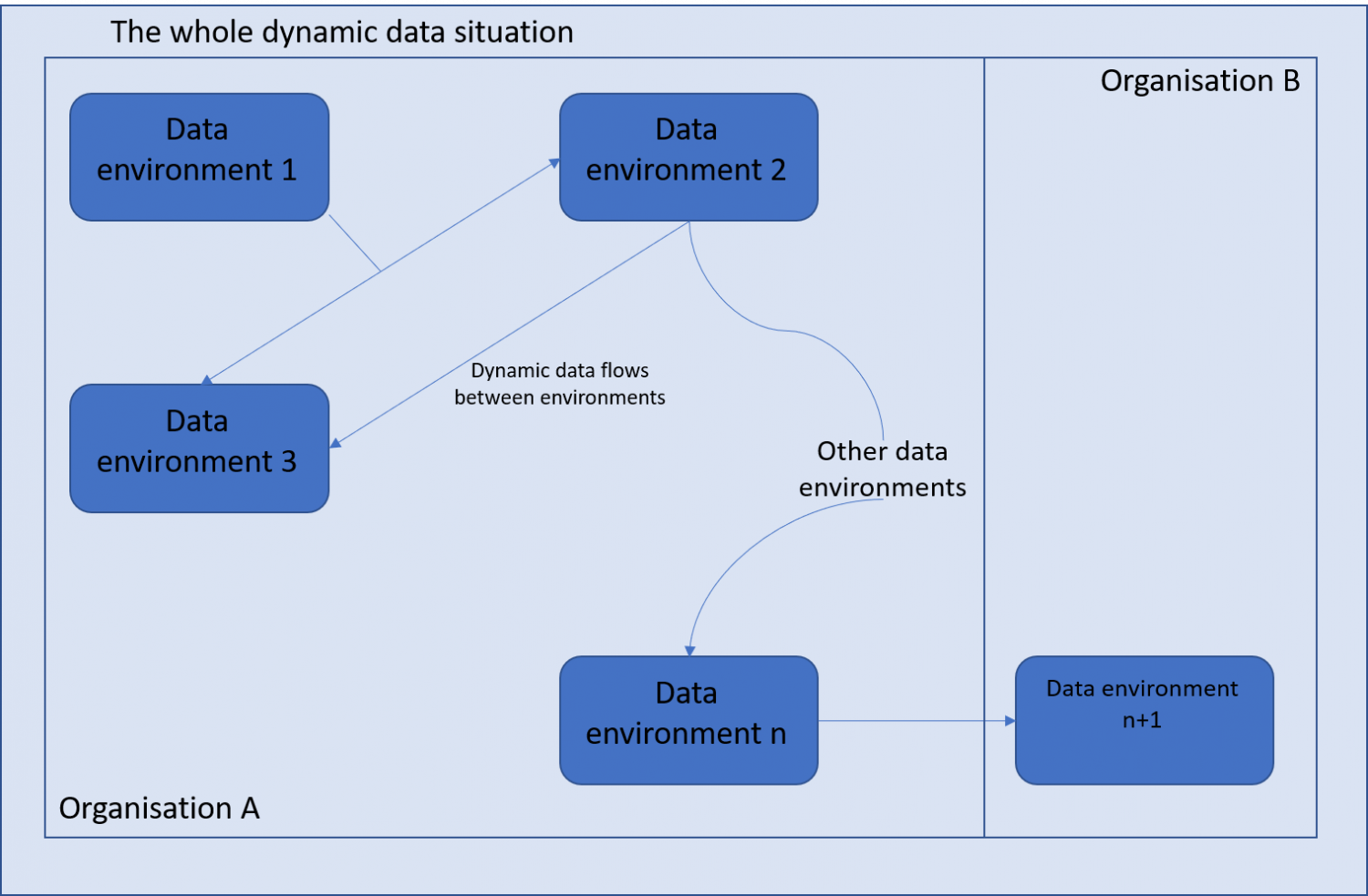
Hình 2. Các môi trường dữ liệu trong một tình huống dữ liệu
Ví dụ: trong Hình 2, chúng ta thấy dữ liệu truyền qua một số môi trường khác nhau. Hầu hết các môi trường đều nằm trong Tổ chức A, nhưng trong môi trường dữ liệu n+1, dữ liệu được chuyển đến Tổ chức B, có thể do chia sẻ dữ liệu hoặc do Tổ chức B đang xử lý dữ liệu thay mặt cho A. Tình huống dữ liệu như khi đó, tổng thể bao gồm tất cả các môi trường và luồng dữ liệu của chúng được tổng hợp lại, cho dù trong Tổ chức A hay B. Bên kiểm soát dữ liệu là người xác định mục đích và phương tiện xử lý thiết yếu và có thể là một hoặc nhiều người ở Tổ chức A, hoặc Tổ chức B, hoặc cả hai. Tình huống dữ liệu không bị giới hạn ở tập hợp trách nhiệm của một tổ chức cụ thể hoặc một người nắm giữ vai trò cụ thể.
Mặc dù môi trường dữ liệu có thể được coi là bối cảnh riêng biệt cho dữ liệu nhưng chúng được kết nối với nhau bằng sự chuyển động của dữ liệu (và con người) giữa chúng. Bằng cách ánh xạ luồng dữ liệu từ thời điểm dữ liệu được thu thập đến thời điểm sau đó chúng được chia sẻ hoặc phát hành, bạn sẽ có thể xác định các tham số cho tình huống dữ liệu của mình. Trước khi minh họa ý tưởng này trong các ví dụ đưa ra dưới đây, cần nhắc lại rằng việc xác định trách nhiệm ngay cả trong một luồng dữ liệu đơn giản có thể phức tạp và cần được xem xét theo từng trường hợp một. Các ví dụ dưới đây chỉ nhằm minh họa cách các yếu tố khác nhau sẽ phát huy tác dụng khi tìm ra ai chịu trách nhiệm về những gì dọc theo luồng dữ liệu. Những yếu tố đó bao gồm, ngoài việc ai là người xác định mục đích và phương tiện xử lý thiết yếu:
Đặc điểm kỹ thuật của dữ liệu được chia sẻ
Đặc điểm kỹ thuật của môi trường nhận, tức là ai sẽ có quyền truy cập vào dữ liệu được chia sẻ cũng như cách thức và những thông tin khác có trong môi trường nhận.
Ví dụ tình huống dữ liệu 1: Chia sẻ đơn giản
Giả thiết, tổ chức A thu thập dữ liệu cá nhân của các khách hàng của nó. Ta gọi đây là môi trường 1. Như một phần của các hoạt động xử lý, tổ chức A có kế hoạch chia sẻ phiên bản dữ liệu được kiểm soát tiết lộ với tổ chức B - tổ chức muốn sử dụng nó để hỗ trợ việc cung cấp dịch vụ tốt hơn cho các khách hàng của mình. Tổ chức A đồng ý chia sẻ bản trích xuất dữ liệu - hoặc có lẽ bắt buộc phải làm như vậy như một phần trong thỏa thuận dịch vụ của mình. Để làm điều này:
Nó sử dụng các kỹ thuật ẩn danh để loại bỏ bớt khả năng tái nhận diện các khách hàng. Tuy nhiên, nó để lại một số biến số quan trọng - được tổ chức B đặc biệt quan tâm - không thay đổi. Điều này được hiểu là bản trích xuất dữ liệu đó (được chia sẻ cho tổ chức B) vẫn còn nằm trong môi trường của tổ chức A và vẫn là dữ liệu cá nhân - vì tổ chức A có phương tiện để tái nhận diện dữ liệu đó.
Nó kiểm soát môi trường chia sẻ bằng cách sử dụng thỏa thuận chia sẻ dữ liệu, ví dụ, thường với các nội dung: (a) chỉ định cách tổ chức B có thể lưu giữ dữ liệu, phân tích dữ liệu và ai có thể truy cập dữ liệu đó; (b) cấm B chia sẻ hoặc phát hành bất kỳ phần nào của dữ liệu mà không có sự đồng ý trước của A; (c) yêu cầu B lưu giữ dữ liệu một cách an toàn và chứng minh việc hủy dữ liệu vào thời điểm đã thỏa thuận và (d) cho phép A kiểm tra B về việc xử lý dữ liệu.
Sau khi hợp đồng này được ký kết, tập hợp dữ liệu (dataset) sẽ được chuyển đến B. Môi trường của B là môi trường 2.
Hình 3 minh họa sự di chuyển có chủ ý của dữ liệu từ môi trường 1 sang môi trường 2. Luồng dữ liệu giữa A và B xác định các tham số của tình huống dữ liệu. Bằng cách sử dụng Thỏa thuận chia sẻ dữ liệu để đặt các biện pháp kiểm soát quản trị và cơ sở hạ tầng trên môi trường 2, tổ chức A quản lý một số rủi ro tiết lộ liên quan đến tình huống dữ liệu. Dữ liệu (được kiểm soát tiết lộ) trong môi trường 2 của B có thể được coi là rủi ro thấp (và thậm chí có thể không đáng kể) mặc dù chúng chứa một số biến số chính chi tiết. Điều này là do bằng cách đặt các biện pháp kiểm soát đối với môi trường, họ đang quản lý hiệu quả quyền truy cập ‘ai’ và ‘như thế nào’. Những yếu tố này có thể làm giảm rủi ro đáng kể và trong những trường hợp này, dữ liệu hiện do B nắm giữ có thể được ẩn danh về mặt chức năng chứ không phải dữ liệu cá nhân. Liệu điều này có đạt được hay không cũng sẽ phụ thuộc vào chi tiết của dữ liệu và các dữ liệu khác mà B nắm giữ. Tại thời điểm này, có thể cần phải phân tích rủi ro - và thực sự đây chính xác là điều mà việc kiểm tra tình huống dữ liệu hướng bạn tới: có bất kỳ tình huống khả thi nào mà dữ liệu đó có thể được nhận diện lại hay không.
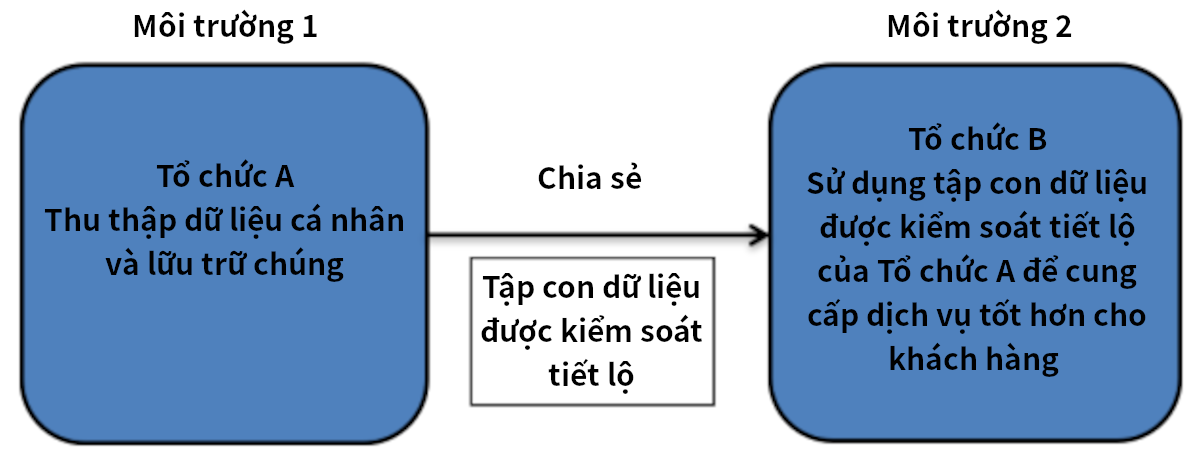
Hình 3. Luồng dữ liệu giữa 2 môi trường trong chia sẻ đơn giản
Vì vậy, hiện tại chúng ta sẽ giả định rằng dữ liệu do B nắm giữ được ẩn danh về mặt chức năng và do đó không mang tính cá nhân. Câu hỏi quan trọng trở thành: B có đơn giản là người dùng trong tình huống dữ liệu này không? Vâng, có và không! Dữ liệu mà họ đang nắm giữ không phải là dữ liệu cá nhân và do đó - theo định nghĩa - đối với những dữ liệu đó, họ là người dùng. Tuy nhiên, B đã tham gia vào việc xác định mục đích xử lý dữ liệu mà A lưu giữ. Mặc dù có nhiều sắc thái phức tạp có thể xảy ra trong cách viết Thỏa thuận chia sẻ dữ liệu, giả định mặc định trong thỏa thuận này là B trở thành bên kiểm soát dữ liệu chung cho dữ liệu của A - liên quan đến quá trình xử lý cần thiết cho mục đích sử dụng cụ thể này.
Một khi bạn đã hiểu rõ điều đó, thì một câu hỏi sẽ nảy sinh là tại sao lại phải ẩn danh; tại sao không chia sẻ dữ liệu cá nhân? Có một số lý do tại sao không. Thứ nhất, chia sẻ dữ liệu cá nhân là một hình thức xử lý khác với việc chia sẻ dữ liệu theo cách không mang tính cá nhân. Nếu dữ liệu được ẩn danh thì trường hợp sử dụng gần như chắc chắn là thống kê/nghiên cứu và do đó sẽ không bị coi là không phù hợp với mục đích ban đầu là thu thập dữ liệu. Thứ hai, vì dữ liệu được ẩn danh về mặt chức năng nên A có thể tự tin chia sẻ dữ liệu và sẽ đáp ứng các nghĩa vụ riêng của họ trước pháp luật. Thứ ba, việc B có tư cách là người kiểm soát dữ liệu có nghĩa là nó đang phân chia rủi ro của phần được chia sẻ một cách tương ứng, do đó A sẽ sẵn sàng chia sẻ hơn. Thứ tư, B sẽ không đảm nhận mọi trách nhiệm của người kiểm soát dữ liệu đối với dữ liệu của A - ví dụ: nó sẽ không phải đáp ứng các yêu cầu truy cập của chủ thể dữ liệu (vì dữ liệu mà nó có quyền truy cập được ẩn danh về mặt chức năng và do đó theo định nghĩa, nó sẽ không có khả năng nhận diện các chủ thể dữ liệu cá nhân). Trách nhiệm của bên kiểm soát dữ liệu của B sẽ được quy định cụ thể trong Thỏa thuận chia sẻ dữ liệu (do đó sẽ là thỏa thuận giữa bên kiểm soát với bên kiểm soát). Tuy nhiên, về bản chất, họ có thể tóm tắt là xử lý dữ liệu một cách cẩn thận như đối với dữ liệu cá nhân ban đầu của bạn. Cuối cùng, tính năng ẩn danh theo chức năng bảo vệ tất cả các bên trong thỏa thuận này: A, B và các chủ thể dữ liệu, đồng thời cho phép chia sẻ dữ liệu hữu ích vì lợi ích công cộng.
Ví dụ tình huống dữ liệu 2: phát hành dữ liệu như là dữ liệu mở
Việc nắm bắt được khái niệm về dữ liệu mở vốn là cốt lõi của động lực minh bạch làm nền tảng cho nhiều phát hành dữ liệu theo định hướng chính sách.
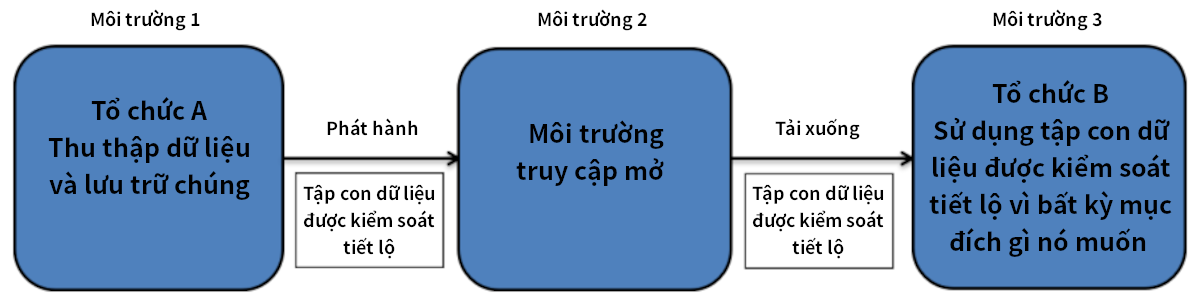
Hình 4. Luồng dữ liệu cho các môi trường phát hành mở trong chia sẻ đơn giản
Trong môi trường ít hạn chế hơn này, như trên Hình 4, rủi ro liên quan đến những dữ liệu này có thể không được coi là thấp. Tổ chức A không còn kiểm soát ai và cách truy cập dữ liệu nữa. Ở nơi quyền truy cập thực sự mở, bất kỳ ai cũng có quyền truy cập Internet đều có thể tải xuống dữ liệu và làm bất cứ điều gì họ muốn với chúng. Tổ chức B trong trường hợp này chỉ đơn giản là một trong những người sử dụng dữ liệu, tải xuống dữ liệu từ môi trường truy cập mở. Họ không có trách nhiệm và thậm chí không có nghĩa vụ phải thông báo cho A về việc họ sử dụng dữ liệu. Rủi ro của bản phát hành này hoàn toàn nằm ở A (và các chủ thể dữ liệu). Cuối cùng, việc phát hành vào môi trường dữ liệu mở có nghĩa là về nguyên tắc, dữ liệu có thể được liên kết với dữ liệu khác được lưu giữ ở bất kỳ đâu trên thế giới, điều này sẽ chỉ làm tăng số lượng các kịch bản khả thi (có khả năng được sử dụng hợp lý) để tái nhận diện.
Điều cần làm rõ ở đây là, để ẩn danh dữ liệu về mặt chức năng trong tình huống dữ liệu 2, Tổ chức A cần phải đảm bảo rằng dữ liệu đủ điều kiện là thông tin ẩn danh, điều đó ngụ ý rằng chúng sẽ bị hạn chế hơn đáng kể so với trong tình huống dữ liệu 1. Điều này có vẻ hiển nhiên, nhưng việc không hiểu điểm cơ bản rằng việc phát hành dữ liệu cần phải phù hợp với môi trường phát hành của chúng là nguyên nhân chính dẫn đến các ví dụ được công bố rộng rãi về các tập hợp dữ liệu ẩn danh kém.
Ví dụ tình huống dữ liệu 3: chia sẻ đơn giản với phát hành thứ cấp mở
Hãy phát triển sâu hơn các khái niệm được nêu trong hai tình huống dữ liệu đầu tiên và tưởng tượng rằng B muốn công bố một số kết quả phân tích từ dữ liệu đó một cách công khai. Ví dụ: họ có thể muốn công bố bảng tổng hợp về việc mua sắm theo các nhóm nhân khẩu học chính như một phần của sáng kiến minh bạch. Kết quả đầu ra tổng hợp vẫn là dữ liệu và do đó việc phát hành như vậy sẽ mở rộng và thực sự làm phức tạp thêm tình huống dữ liệu. Môi trường thứ ba trong chuỗi là môi trường mở. Bức tranh mới về luồng dữ liệu được hiển thị trên Hình 5. Đây là một ví dụ về cái mà chúng ta gọi là tình huống dữ liệu hai bước. Bước đầu tiên được mô tả hoàn toàn bằng tình huống dữ liệu 1 ở trên, nhưng bước thứ hai thực chất là một tình huống dữ liệu mới và cần phân tích riêng.
Luồng dữ liệu giữa A, B và môi trường truy cập mở xác định các tham số về tình huống dữ liệu của B đối với dữ liệu khách hàng được ẩn danh.
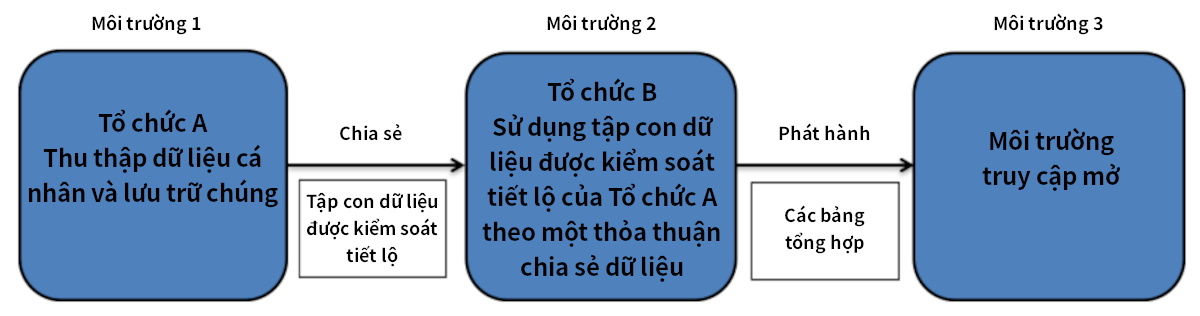
Hình 5. Luồng dữ liệu giữa nhiều môi trường
Tổ chức B, như được quy định trong Thỏa thuận chia sẻ dữ liệu với tổ chức A, không thể tiết lộ dữ liệu ẩn danh được cung cấp cho nó ở dạng ban đầu mà không có sự cho phép của A. Với tư cách là bên cùng kiểm soát dữ liệu, B và/hoặc A nên: (i) tiến hành phân tích rủi ro tiết lộ về việc phát hành dự kiến đầu ra vào môi trường truy cập mở và (ii) nếu cần, sử dụng thêm biện pháp kiểm soát tiết lộ dữ liệu để giảm bớt sự rủi ro của dữ liệu đến mức không đáng kể. Quy trình chính xác cho việc này sẽ được quy định cụ thể trong Thỏa thuận chia sẻ dữ liệu nhưng thông thường B sẽ tự thực hiện đánh giá rủi ro trước khi đề xuất kết quả đầu ra cụ thể cho A.
Ví dụ tình huống dữ liệu 4: chia sẻ đơn giản với bản phát hành thứ cấp được kiểm soát
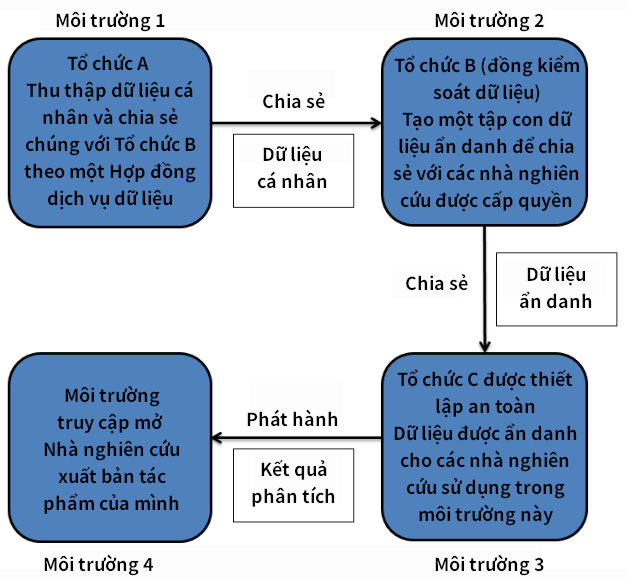
Hình 6. Sự dịch chuyển của dữ liệu qua nhiều môi trường
Trong ví dụ này, như trên Hình 6, chúng ta xem xét luồng dữ liệu qua các môi trường liên quan đến dữ liệu cá nhân và dữ liệu được ẩn danh để không nhận diện lại được. Giả thiết rằng tổ chức A thu thập dữ liệu khách hàng ở khu vực của mình. Theo luật, nó có quyền chia sẻ một số dữ liệu đó với một bên B để hỗ trợ cho công việc của mình. Việc chia sẻ dữ liệu được chính thức hóa theo Thỏa thuận chia sẻ dữ liệu quy định rằng A và B là các bên cùng kiểm soát dữ liệu đối với những dữ liệu đó. Điều này không nhất thiết có nghĩa là việc phân chia trách nhiệm sẽ bình đẳng giữa hai tổ chức – Thỏa thuận chia sẻ dữ liệu phải quy định tổ chức nào chịu trách nhiệm về việc gì. Gọi môi trường của A là môi trường 1.
Tổ chức B, như một phần trong trách nhiệm của nó (và theo thỏa thuận với Tổ chức A), tạo ra một tập hợp con dữ liệu đã được ẩn danh và cung cấp dữ liệu đó trong môi trường an toàn để các nhà nghiên cứu được phê duyệt và cấp quyền sử dụng lại. Gọi môi trường của Tổ chức B là môi trường 2, được thiết lập bảo mật theo cách đảm bảo rằng dữ liệu được ẩn danh về mặt chức năng. Nó đặt ra những hạn chế về việc ai có thể truy cập dữ liệu, cách truy cập dữ liệu và những thông tin phụ trợ nào có thể được đưa vào và ra khỏi môi trường phòng thí nghiệm an toàn. Gọi môi trường an toàn của phòng thí nghiệm C là môi trường 3.
Một nhà nghiên cứu được phê duyệt và công nhận thực hiện phân tích dữ liệu của mình trong phòng thí nghiệm an toàn, tạo ra kết quả thống kê cần thiết để viết bài báo về kết quả nghiên cứu của mình. Những kết quả đầu ra này trước tiên được nhân viên phòng thí nghiệm an toàn kiểm tra để đảm bảo rằng chúng không bị tiết lộ không mong muốn, trong trường hợp đó chúng sẽ được thông qua là 'an toàn'. Nhà nghiên cứu viết và xuất bản công khai nghiên cứu của mình một cách hợp lệ, trong đó có một số kết quả phân tích. Nền tảng xuất bản của nghiên cứu là môi trường truy cập mở, gọi là môi trường 4.
Như trong hai ví dụ đầu tiên, một trong những vấn đề chính mà đặc biệt muốn được nêu bật là dữ liệu trong môi trường này có thể được coi là ẩn danh về mặt chức năng, nhưng trong môi trường khác (chẳng hạn như ấn phẩm của nhà nghiên cứu), điều này có thể không còn đúng nữa. Do đó, trong ví dụ này, kết quả phân tích của nhà nghiên cứu phải được phòng thí nghiệm bảo mật kiểm tra và xác minh là ‘an toàn’ trước khi nhà nghiên cứu đó có thể mang dữ liệu đi.
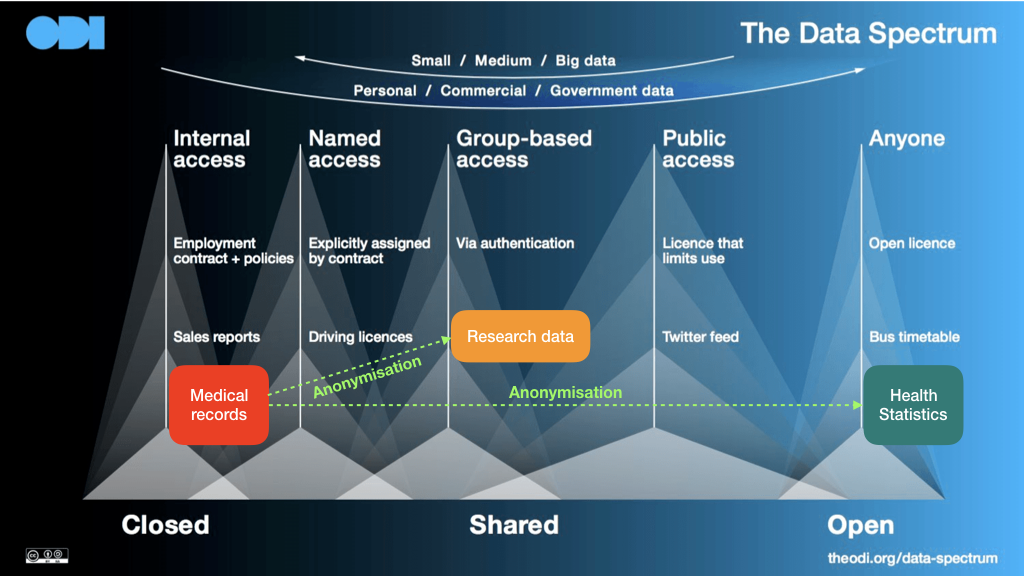
Hình 7. Dữ liệu cá nhân nhạy cảm có thể trở thành dữ liệu mở bằng các kỹ thuật ẩn danh đúng cách xuyên suốt phổ dữ liệu, từ “đóng” sang “chia sẻ” rồi sang “mở”
Ví dụ này cũng cho thấy một điểm quan trọng khác, ấy là một tập hợp dữ liệu cá nhân, kể cả là dữ liệu cá nhân nhạy cảm như hồ sơ y tế cá nhân (Điều 2, khoản 4.b, NĐ13), khi được ẩn danh đúng cách, hoàn toàn có thể dịch chuyển qua toàn bộ phổ dữ liệu, từ dạng “đóng” sang dạng “chia sẻ” và sang dạng “mở”[4] mà bất kỳ ai cũng có thể truy cập được tới nó như được minh họa như trên Hình 7.
Cần nhấn mạnh rằng mặc dù một tình huống dữ liệu có thể phức tạp nhưng nó không nên được coi là một vấn đề khó giải quyết đến mức bạn cảm thấy an toàn hơn khi không cân nhắc việc chia sẻ hoặc phát hành dữ liệu của mình. Tất nhiên, đó có thể là kết luận mà bạn đưa ra sau khi đã làm việc với Khung ADF nhưng nó không phải là điểm khởi đầu. Bạn không nên bỏ qua hàng loạt lợi ích to lớn có thể và thực sự đến từ việc chia sẻ và mở dữ liệu.
Tinh chỉnh trọng tâm của bạn
Thông thường, các luồng dữ liệu mà bạn ánh xạ sẽ phức tạp hơn rất nhiều so với những gì bạn dự tính ban đầu và điều này có thể gây khó khăn. Đôi khi quá trình ánh xạ sẽ làm nổi bật những gì bạn đã biết: rằng tình huống mà bạn đang gặp phải rất phức tạp. Một cách để nhìn thấu sự phức tạp là tinh chỉnh trọng tâm phân tích của bạn.
Tình huống dữ liệu trọng tâm của bạn, cả dữ liệu và môi trường, là đối tượng bạn quan tâm để phân tích. Ví dụ: nếu bạn đang cân nhắc việc chia sẻ dữ liệu với một tổ chức khác thì tổ chức đó sẽ là môi trường dữ liệu trọng tâm và việc di chuyển dữ liệu mà bạn đang cân nhắc chia sẻ vào môi trường đó sẽ là tình huống dữ liệu trọng tâm. Do đó, mục tiêu của bạn ở đây là tinh chỉnh trọng tâm của mình một cách thích hợp và suy nghĩ nghiêm túc về tình huống dữ liệu trọng tâm đó. Để làm được điều này, bạn cần xem xét thêm ba yếu tố nữa.
Phạm vi kiểm soát. Bạn có quyền kiểm soát quyết định và quyền kiểm soát hoạt động đối với những yếu tố nào của luồng dữ liệu? Kiểm soát quyết định cho thấy khả năng thiết lập chính sách, đưa ra các quy tắc và quy định để xử lý. Kiểm soát hoạt động có nghĩa là khả năng đưa ra các quyết định xử lý hàng ngày.
Phạm vi trách nhiệm. Bạn chịu trách nhiệm trực tiếp và gián tiếp đối với những yếu tố nào của luồng dữ liệu? Trách nhiệm có thể đến từ các yêu cầu pháp lý, cân nhắc về đạo đức và/hoặc thỏa thuận. Trách nhiệm trực tiếp là những trách nhiệm mà chỉ có hành động của riêng bạn mới được thực hiện. Trách nhiệm gián tiếp là nơi hành động của người khác nằm trong phạm vi. Việc xác định các trách nhiệm này sẽ cho phép bạn làm rõ các trách nhiệm nào được áp dụng.
Mức độ liên quan. Những yếu tố nào của luồng dữ liệu ảnh hưởng đến tình huống dữ liệu trọng tâm?
Thông thường, bên xử lý sẽ có quyền kiểm soát hoạt động và chịu trách nhiệm trực tiếp nhưng không có quyền kiểm soát quyết định hoặc trách nhiệm gián tiếp. Tuy nhiên, sẽ nảy sinh các tình huống khi bên xử lý ủy quyền hoặc ký hợp đồng phụ thực hiện các nhiệm vụ xử lý cho các bên xử lý phụ, trong trường hợp đó, họ cũng sẽ phải chịu một số trách nhiệm gián tiếp. Theo định nghĩa, bên kiểm soát có quyền kiểm soát quyết định và có thể có quyền kiểm soát hoạt động cũng như trách nhiệm trực tiếp và/hoặc gián tiếp. Điểm thứ hai là các khái niệm về kiểm soát và trách nhiệm áp dụng cho dữ liệu bất kể đó là dữ liệu cá nhân hay không trong khi sự phân biệt giữa bên kiểm soát/bên xử lý được gắn rõ ràng với dữ liệu cá nhân.
Nếu bạn xem xét tình huống dữ liệu 1, A có quyền kiểm soát hoạt động và kiểm soát quyết định cũng như trách nhiệm trực tiếp đối với dữ liệu của chính mình và B có một số quyền kiểm soát quyết định và trách nhiệm gián tiếp. Đối với phiên bản dữ liệu ẩn danh về mặt chức năng, B có quyền kiểm soát hoạt động và một số quyền quyết định cũng như trách nhiệm trực tiếp còn A có quyền kiểm soát quyết định và trách nhiệm gián tiếp. Đây là trường hợp khá phổ biến trong thực tế khi hai bên cùng có quyền kiểm soát.
Điểm mấu chốt ở giai đoạn này là đảm bảo rằng mục tiêu kiểm soát và mục tiêu trách nhiệm của bạn phù hợp với nhau. Nếu không thì có thể bạn đang gặp vấn đề mà việc ẩn danh không phải là giải pháp.
Yếu tố cuối cùng cần được xem xét khi xác định trọng tâm là mức độ liên quan. Một tình huống dữ liệu có thể liên quan nếu nó ảnh hưởng đến rủi ro của môi trường dữ liệu trọng tâm hiện hành nhưng nằm ngoài phạm vi kiểm soát.
Vì vậy, khi kết thúc phần này, bằng cách sử dụng các khái niệm về trách nhiệm, quyền kiểm soát và mức độ liên quan, bạn sẽ tinh chỉnh được tình huống dữ liệu trọng tâm của mình và bằng cách đó làm rõ câu hỏi ẩn danh cụ thể mà bạn muốn giải quyết.
Vài gợi ý
Trong khi việc xác định trách nhiệm thuộc về ai/tổ chức nào trong xử lý dữ liệu cá nhân nhằm tránh sự cố tiết lộ dữ liệu cá nhân không như dự tính và đưa ra được quyết định ẩn danh phù hợp để biến các dữ liệu cá nhân thành các dữ liệu hữu ích an toàn là một công việc phức tạp, thì vấn đề này chỉ là một (thành phần 2) trong mười thành phần của Khung Ra quyết định Ẩn danh (ADF) mà Vương quốc Anh đã và đang phát triển. Điều này cho thấy có nhu cầu rất lớn về một khung tương tự như Khung ADF cho Việt Nam với các gợi ý/hướng dẫn/giải thích/cung cấp các ví dụ cụ thể về cách thức xử lý dữ liệu cá nhân, từ việc kiểm tra tình huống dữ liệu (các thành phần từ 1 đến 6), cho tới phân tích rủi ro tiết lộ (thành phần 7) và quản lý các tác động (các thành phần từ 8 đến 10), được ánh xạ cho phù hợp với các nội dung được nêu trong NĐ13 và các văn bản quy phạm pháp luật có liên quan khác.
Gợi ý bổ sung thêm trường hợp đồng kiểm soát, như được nêu trong bài, với mức độ kiểm soát của từng bên không nhất thiết phải y hệt nhau.
Vài gợi ý khác có liên quan tới bảo vệ dữ liệu cá nhân có thể bổ sung cho bài viết này đã được nêu trong một bài viết khác gần đây[5], chẳng hạn như: (1) Các nguyên tắc dựa vào đó để xây dựng một Khung ADF; (2) Các nguyên tắc tính mở cho tổ chức kiểm soát và/hoặc xử lý dữ liệu cá nhân; (3) Vài kỹ thuật ẩn danh đơn giản; (4) Vài phần mềm nguồn mở tuân thủ GDPR.
Tài liệu tham khảo
[1] Trang web của Chính phủ: Nghị định số 13/2023/NĐ-CP của Chính phủ: Bảo vệ dữ liệu cá nhân: https://vanban.chinhphu.vn/?pageid=27160&docid=207759, truy cập ngày 10/10/2023.
[2] Mark Elliot, Elaine Mackey and Kieron O’Hara (2020): The Anonymisation Decision-Making Framework: European Practitioners’ Guide: https://msrbcel.files.wordpress.com/2020/11/adf-2nd-edition-1.pdf, truy cập ngày 10/10/2023.
[3] THE EUROPEAN PARLIAMENT AND THE COUNCIL OF THE EUROPEAN UNION (2016): General Data Protection Regulation: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32016R0679, truy cập ngày 10/10/2023.
[4] ODI (2019): Anonymisation and Open Data: An introduction to managing the risk of re-identification: https://docs.google.com/document/d/1CoXniaTnQL_4ZyQuji9_MA_YCEElQjx4z1SEdB08c2M/edit, p.7. Truy cập ngày 10/10/2023.
[5] Lê Trung Nghĩa (2023): Nghị định Bảo vệ dữ liệu cá nhân và một vài gợi ý triển khai: DOI: 10.5281/zenodo.8323145
![]()
Giấy phép nội dung: CC BY 4.0 Quốc tế
Tự do tải về bài viết định dạng PDF ở địa chỉ DOI: https://doi.org/10.5281/zenodo.10066982
Tự do tải về bài trình chiếu tại hội thảo ở địa chỉ: https://www.dropbox.com/scl/fi/3upw7oo2i2b0icpsl9gg5/ADF_for_VN.pdf?rlkey=dj54kw3en6wzuab9uxidevjqg&dl=0
Tweet: https://twitter.com/nghiafoss/status/1720288296142815466
![]() Lê Trung Nghĩa, ORCID iD: https://orcid.org/0009-0007-7683-7703
Lê Trung Nghĩa, ORCID iD: https://orcid.org/0009-0007-7683-7703
Viện Nghiên cứu, Đào tạo và Phát triển Tài nguyên Giáo dục Mở (InOER)
Hiệp hội các trường đại học cao đẳng Việt Nam (AVU&C)
(Bài viết cho Hội thảo khoa học quốc gia ‘Dữ liệu cá nhân trong dòng chảy kinh tế số’ do Trường Kinh tế Luật và Quản lý Nhà nước, Đại học Kinh tế TP. Hồ Chí Minh (UEH) và Viện Nghiên cứu Chính sách và Phát triển Phương tiện (IPS) tổ chức ngày 03/11/2023 tại TP. Hồ Chí Minh).
Xem thêm:
Tác giả: Nghĩa Lê Trung
Ý kiến bạn đọc
Những tin mới hơn
Những tin cũ hơn
Blog này được chuyển đổi từ http://blog.yahoo.com/letrungnghia trên Yahoo Blog sang sử dụng NukeViet sau khi Yahoo Blog đóng cửa tại Việt Nam ngày 17/01/2013.Kể từ ngày 07/02/2013, thông tin trên Blog được cập nhật tiếp tục trở lại với sự hỗ trợ kỹ thuật và đặt chỗ hosting của nhóm phát triển...
 Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
Sổ tay Nghiên cứu Mở của Mạng lưới Cao học Toàn cầu Tài nguyên Giáo dục Mở - GO-GN (Global OER - Graduate Network)
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 Các bài toàn văn trong năm 2025
Các bài toàn văn trong năm 2025
 Các bài trình chiếu trong năm 2025
Các bài trình chiếu trong năm 2025
 Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
Tập huấn thực hành ‘Khai thác tài nguyên giáo dục mở’ cho giáo viên phổ thông, bao gồm cả giáo viên tiểu học và mầm non tới hết năm 2025
 Các tài liệu dịch sang tiếng Việt tới hết năm 2025
Các tài liệu dịch sang tiếng Việt tới hết năm 2025
 Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
Loạt bài về AI và AI Nguồn Mở: Công cụ AI; Dự án AI Nguồn Mở; LLM Nguồn Mở; Kỹ thuật lời nhắc;
 Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
Tổng hợp các bài của Nhóm các Nhà cấp vốn Nghiên cứu Mở (ORFG) đã được dịch sang tiếng Việt
 Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
Tổng hợp các bài của Liên minh S (cOAlition S) đã được dịch sang tiếng Việt
 Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
Bàn về 'Lợi thế của doanh nghiệp Việt là dữ liệu Việt, bài toán Việt' - bài phát biểu của Bộ trưởng Nguyễn Mạnh Hùng ngày 21/08/2025
 ‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
‘KHUYẾN NGHỊ VÀ HƯỚNG DẪN TRUY CẬP MỞ KIM CƯƠNG cho các cơ sở, nhà cấp vốn, nhà bảo trợ, nhà tài trợ, và nhà hoạch định chính sách’ - bản dịch sang tiếng Việt
 Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
Tọa đàm ‘Vai trò của Tài nguyên Giáo dục Mở trong chuyển đổi số giáo dục đại học’ tại Viện Chuyển đổi số và Học liệu - Đại học Huế, ngày 12/09/2025
 12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 11. Hugging Face Transformers
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn
 Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
Khóa Thực hành khai thác Tài nguyên Giáo dục Mở No2/2025 tại Trường Đại học Nguyễn Tất Thành, 19 và 26/08/2025. Ngày 1.
 Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
Hướng dẫn kỹ thuật lời nhắc. Kỹ thuật viết lời nhắc. Lời nhắc Tái Hành động (ReAct)
 Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
Thông cáo báo chí của Liên minh S về Truy cập Mở trong giai đoạn 2026-2030 - bản dịch sang tiếng Việt
 DigComp 3.0: Khung năng lực số châu Âu
DigComp 3.0: Khung năng lực số châu Âu
 ‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
‘Chiến thắng cuộc đua: KẾ HOẠCH HÀNH ĐỘNG AI CỦA NƯỚC MỸ’ - bản dịch sang tiếng Việt
12 dự án AI Nguồn Mở hàng đầu để bổ sung vào kho công nghệ của bạn. 9. OpenCV
 ‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
‘Sinh viên là đồng tác giả: Cảm xúc về thành tích, niềm tin về việc viết và quyết định xuất bản Tài nguyên Giáo dục Mở’ - bản dịch sang tiếng Việt
 cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
cOAlition S củng cố cam kết Truy cập Mở trong khi thúc đẩy giai đoạn chiến lược tiếp theo
 Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
Tài nguyên Giáo dục Mở trong kỷ nguyên AI
Hướng dẫn kỹ thuật lời nhắc. Các tác nhân. Giới thiệu các tác nhân AI
Hướng dẫn kỹ thuật lời nhắc. Giới thiệu. Các thành phần của lời nhắc
Các bài trình chiếu trong năm 2025
 Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
Tọa đàm ‘Xây dựng nhà trường số dựa trên nền tảng năng lực số và ứng dụng công nghệ 4.0, AI’ tại Trường Cao đẳng Long An, 05/08/2025
 Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025
Tập huấn về Tài nguyên Giáo dục Mở nhân sự kiện “Đại hội Đại biểu Liên Chi hội Thư viện Đại học phía Nam”, ngày 07/08/2025

